自动编码器及其各类改进还挺有意思的,可以用来降噪降维,挺具有潜力的,也看了蛮多内容了,稍微整理一个了解路径吧
自动编码器及其各类改进模型
各种编码器的基本介绍,比较详细,代码是keras,未测试:
[自编码器:理论+代码]:自编码器、栈式自编码器、欠完备自编码器、稀疏自编码器、去噪自编码器、卷积自编码器
各种编码器的基本介绍及pytorch实现,代码测试可通:
PyTorch 学习笔记(九):自动编码器(AutoEncoder)
关于稀疏自动编码器/逐层预训练的讨论
推荐:为什么稀疏自编码器很少见到多层的? - 科言君的回答 - 知乎 https://www.zhihu.com/question/41490383/answer/103006793

中间层的维度
为了尽量学到有意义的表达,我们会给隐层加入一定的约束。从数据维度来看,常见以下两种情况:
n>p,即隐层维度小于输入数据维度。也就是说从x→h的变换是一种降维的操作,网络试图以更小的维度去描述原始数据而尽量不损失数据信息。实际上,当每两层之间的变换均为线性,且监督训练的误差是二次型误差时,该网络等价于PCA!没反应过来的童鞋可以反思下PCA是在做什么事情。
n<p,即隐层维度大于输入数据维度。这又有什么用呢?其实不好说,但比如我们同时约束h的表达尽量稀疏(有大量维度为0,未被激活),此时的编码器便是大名鼎鼎的“稀疏自编码器”。可为什么稀疏的表达就是好的?这就说来话长了,有人试图从人脑机理对比,即人类神经系统在某一刺激下,大部分神经元是被抑制的。个人觉得,从特征的角度来看更直观些,稀疏的表达意味着系统在尝试去特征选择,找出大量维度中真正重要的若干维。
栈式编码器(Stack Autoencoder)
有过深度学习基础的童鞋想必了解,深层网络的威力在于其能够逐层地学习原始数据的多种表达。每一层的都以底一层的表达为基础,但往往更抽象,更加适合复杂的分类等任务。
堆叠自编码器实际上就在做这样的事情,如前所述,单个自编码器通过虚构x→h→x的三层网络,能够学习出一种特征变化h=fθ(x)(这里用θ表示变换的参数,包括W,b和激活函数)。实际上,当训练结束后,输出层已经没什么意义了,我们一般将其去掉,即将自编码器表示为

之前之所以将自编码器模型表示为3层的神经网络,那是因为训练的需要,我们将原始数据作为假想的目标输出,以此构建监督误差来训练整个网络。等训练结束后,输出层就可以去掉了,我们关心的只是从x到h的变换。
接下来的思路就很自然了——我们已经得到特征表达h,那么我们可不可以将
h再当做原始信息,训练一个新的自编码器,得到新的特征表达呢?当然可以!这就是所谓的堆叠自编码器(Stacked Auto-Encoder, SAE)。Stacked就是逐层垒叠的意思,跟“栈”有点像。UFLDL教程将其翻译为“栈式自编码”,anyway,不管怎么称呼,都是这个东东,别被花里胡哨的专业术语吓到就行。当把多个自编码器Stack起来之后,这个系统看起来就像这样:

亦可赛艇!这个系统实际上已经有点深度学习的味道了,即learning multiple levels of representation and abstraction(Hinton, Bengio, LeCun, 2015)。需要注意的是,整个网络的训练不是一蹴而就的,而是逐层进行。按题主提到的结构n,m,k结构,实际上我们是先训练网络n→m→n,得到n→m的变换,然后再训练m→k→m,得到m→k的变换。最终堆叠成SAE,即为n→m→k的结果,整个过程就像一层层往上盖房子,这便是大名鼎鼎的layer-wise unsuperwised pre-training(逐层非监督预训练),正是导致深度学习(神经网络)在2006年第3次兴起的核心技术。
逐层预训练:
题主提到,为什么训练稀疏自编码器为什么一般都是3层的结构,实际上这里的3层是指训练单个自编码器所假想的3层神经网络,这对任何基于神经网络的编码器都是如此。多层的稀疏自编码器自然是有的,只不过是通过layer-wise pre-training这种方式逐层垒叠起来的,而不是直接去训练一个5层或是更多层的网络。
为什么要这样?实际上,这正是在训练深层神经网络中遇到的问题。直接去训练一个深层的自编码器,其实本质上就是在做深度网络的训练,由于梯度扩散等问题,这样的网络往往根本无法训练。这倒不是因为会破坏稀疏性等原因,只要网络能够训练,对模型施加的约束总能得到相应的结果。
但为什么逐层预训练就可以使得深度网络的训练成为可能了呢?有不少文章也做过这方面的研究。一个直观的解释是,预训练好的网络在一定程度上拟合了训练数据的结构,这使得整个网络的初始值是在一个合适的状态,便于有监督阶段加快迭代收敛。
笔者曾经基于 MNIST数据集,尝试了一个9层的网络完成分类任务。当随机初始化时,误差传到底层几乎全为0,根本无法训练。但采用逐层预训练的方法,训练好每两层之间的自编码变换,将其参数作为系统初始值,然后网络在有监督阶段就能比较稳定的迭代了。
当然,有不少研究提出了很好的初始化策略,再加上现在常用的dropout、ReLU,直接去训练一个深层网络已经不是问题。这是否意味着这种逐层预训练的方式已经过时了呢?这里,我想采用下Bengio先生2015年的一段话作为回答:
Stacks of unsupervised feature learning layers are STILL useful when you are in a regime with insufficient labeled examples, for transfer learning or domain adaptation. It is a regularizer. But when the number of labeled examples becomes large enough, the advantage of that regularizer becomes much less. I suspect however that this story is far from ended! There are other ways besides pre-training of combining supervised and unsupervised learning, and I believe that we still have a lot to improve in terms of our unsupervised learning algorithms.
最后,多说一句,除了AE和SAE这种逐层预训练的方式外,还有另外一条类似的主线,即限制玻尔兹曼机(RBM)与深度信念网络(DBN)。这些模型在神经网络/深度学习框架中的位置,可以简要总结为下图。
感知机、神经网络、自动编码器、受限玻尔兹曼机
这张图很酷,算是厘清了感知机、神经网络、自动编码器、受限玻尔兹曼机啥的关系了。
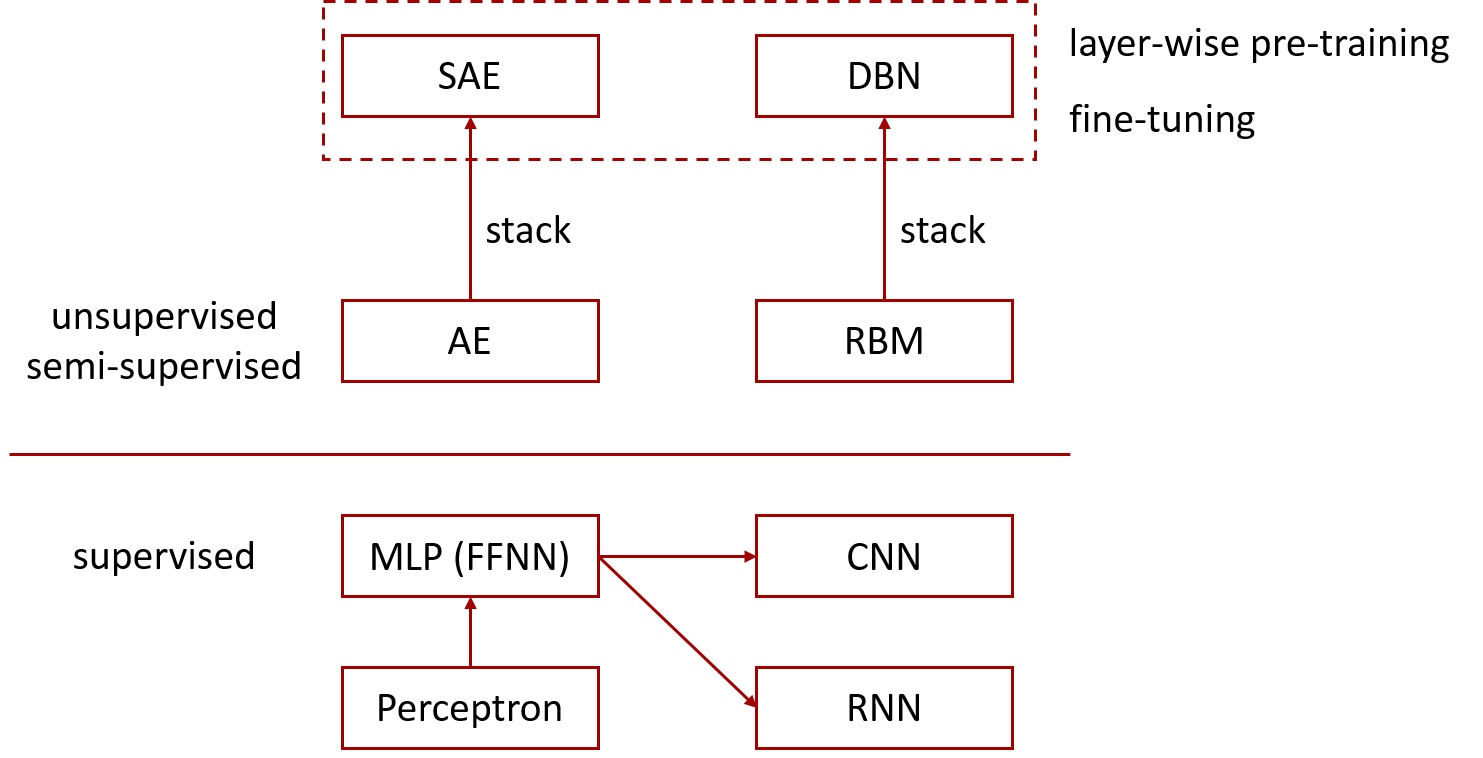
订正:感谢@Detective 夏恩指正,RBM堆叠起来是Deep Boltzmann Machines, 再加一个分类器才是DBN,供阅读上图时参考。*
变分编码器
基本介绍和代码:
PyTorch 学习笔记(九):自动编码器(AutoEncoder)
详细推导:
强推,变分自编码器(一):原来是这么一回事,以及他blog里继续的内容