也许今后有机会在NLP深入探索了,说实在的,对NLP唯一的接触还是大三做hadoop/spark的时候为了结合爬虫和词云,了解一些中文分词,像是结巴分词印象就还蛮深刻的。反正,先尝试了解了解吧,干就完了!
习惯了CV的东西,一下转到看NLP,不知道是不是心理因素,还是真的思路和focus的东西不一样,感觉好容易忘哦,还是写下blog简单记录下一些小知识点,免得看了就忘的蠢事
文本表示模型
词袋模型
文本是一种非结构化数据,所以我们首先需要找到合适的方法表示文本数据,最基础的文本表示模型就是词袋模型,将每篇文章都看做是一袋子词,不care词在哪里出现、出现的顺序
具体而言,就是将整段文字以词为单位切开,从而每篇文章都能表示成一个长向量,向量的每个维度都代表一个单词,而该维的权重是这个词在文章中的重要程度,常用TF-IDF来计算:
TF-IDF(t,d)=TF(t,d) × IDF(t)
真中T F(t,d) 为单词t 在艾档d 中出现的频率, ID F( t) 是逆文挡频率,
用来衡量单词t 对表达语义所起的重要性,表示为
IDF(t) = log ( 文章总数 / (出现单词t的文章总数+1) )
直观的解释是如果一个单词在很多文章里都出现过, 那么可能是一个比较通用的词汇,比如the a an 这种冠词吧,对于区分某篇文章特殊语义的贡献较小。因此,对权重做一定惩罚。
N-gram
如果单纯看单词的出现,肯定还是很粗糙的,毕竟语言是流动的文字而非定格的塑像,所以可以在词袋模型的基础上,将连续出现的n个词组成的词组(N-gram)也作为一个单独的特征放到向量空间中,构成N-gram模型。
另外,同一个词可能有多种词性变化却具有相似的含义。在实际应用中,一般会对单词进行词干抽取( Word Stemming )处理,即将不同词性的单词统一成为同一词干的形式。
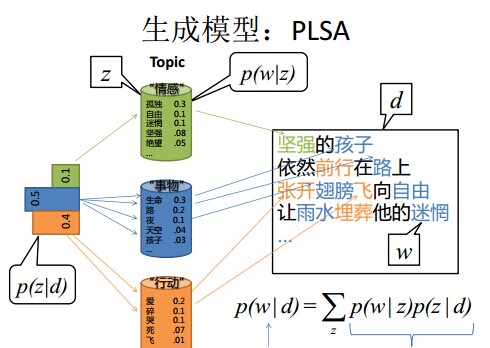
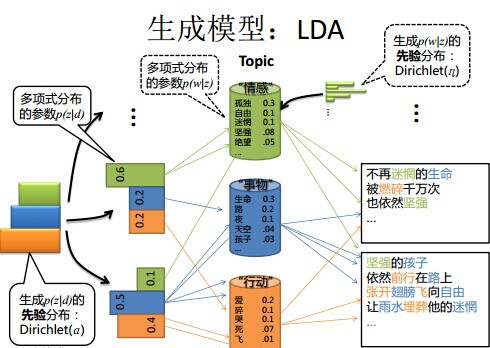
主题模型
pLSA、LDA 一文详解LDA主题模型
LDA 就是 PLSA 的贝叶斯化版本。下面两张图片很好的体现了两者的区别:
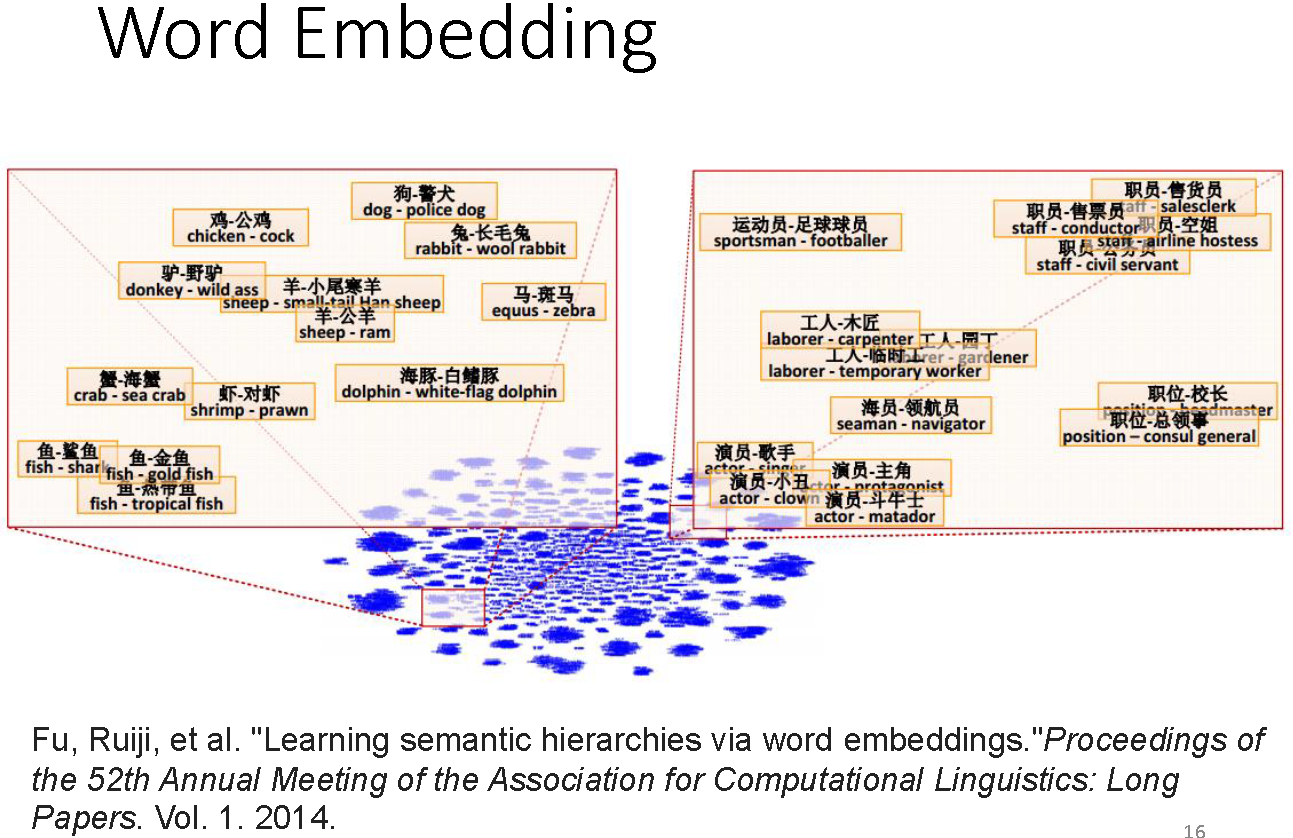
词嵌入和深度学习模型
词嵌入是将词向量化的一种模型,核心思想:把每个词都映射到低维空间中(通常K=50~300),生成对应的K维稠密向量,而其中的每个维度可以看做是一个隐含的主题,只不过并不像主题模型中的主题那样直观。
每个词为K维向量,那么N个词的文章就是NxK的矩阵,而可以继续借助深度学习提取各个层次特征的能力,从这个矩阵中提取出更work的特征,这一点和CNN用于CV一样的,从简单的线条信息到组成具有意义的物体,深度学习也可以再NLP中通过CNN、LSTM抓取文本的特性,同时比起传统的全连接而言,参数跟少。
采样方法
一种采样是知道分布的类型,需要估计分布的参数,比如GMM,EM求解最大似然法。此类简单的问题,可以通bootstrap和刀切法去多次采样,然后再对多次采样的结果求解
另一种是采样得到的样本集可以作为非参数模型,就是用比较少的、离散的样本点来近似总体分布,并刻画总体分布中的不确定性。从这个角度来说采样其实也是一种信息降维,可以起到简化问题的作用
拒绝采样
重要性采样
很多时候,采样的最终目的并不是为了得到样本,而是为了进行一些后续任务,如预测变量取值,这通常表现为一个求函数期望的形式。重要生采样就是用于计算函数fx)在目标分布p(x)上的积分(函数期望),即
E[f] = ∫ f(x) · p(x) dx
首先,找一个比较容易抽样的参考分布q(x) ,并令w(x) = p(x) / q(x)
则有
E[f] = ∫ f(x)·w(x)·q(x) dx
这里w(x)可以看做是x的重要性权重,由此,可以从参考分布q(x)中抽取出N个样本{x},然后利用下列公式来估计E[f]:
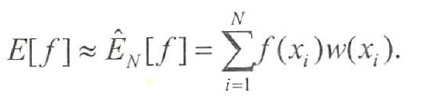
如果不需要计算函数积分,只想从目标分布p(x)中采样出若干样本,则可以用重要性重采样( Sampling-Importance Re-sampling , SIR ),先在参考分布q(x)中抽取N个样本{xi},然后按照他们对应的重要性权重{w(xi)}对这些样本进行重新采样(这是个简单的针对有限离散分布的采样),最终得到的样本服从目标分布p(x)
在实际应用中,如果是高维空间的随机向量, 拒绝采样和重要性重采样经常难以寻找合适的参考分布,采样效率低下(样本的接受慨率小或重要性权重低),此时可以考虑马尔可夫蒙特卡洛采样法,常见的有MH采样法和Gibbs采样法。
重要的模型
word embedding / word2vec
[NLP] 秒懂词向量Word2vec的本质 - 穆文的文章 - 知乎 https://zhuanlan.zhihu.com/p/26306795
李宏毅老师的视频,李宏毅2020机器学习深度学习(完整版)国语-P22,https://www.bilibili.com/video/BV1JE411g7XF?p=22
One-hot编码词后,输入,通过一层线性的hidden layer,通过softmax输出与类别同维度的结果,即属于相应词的概率
如果有多个输入,注意hidden layer是共享权重的
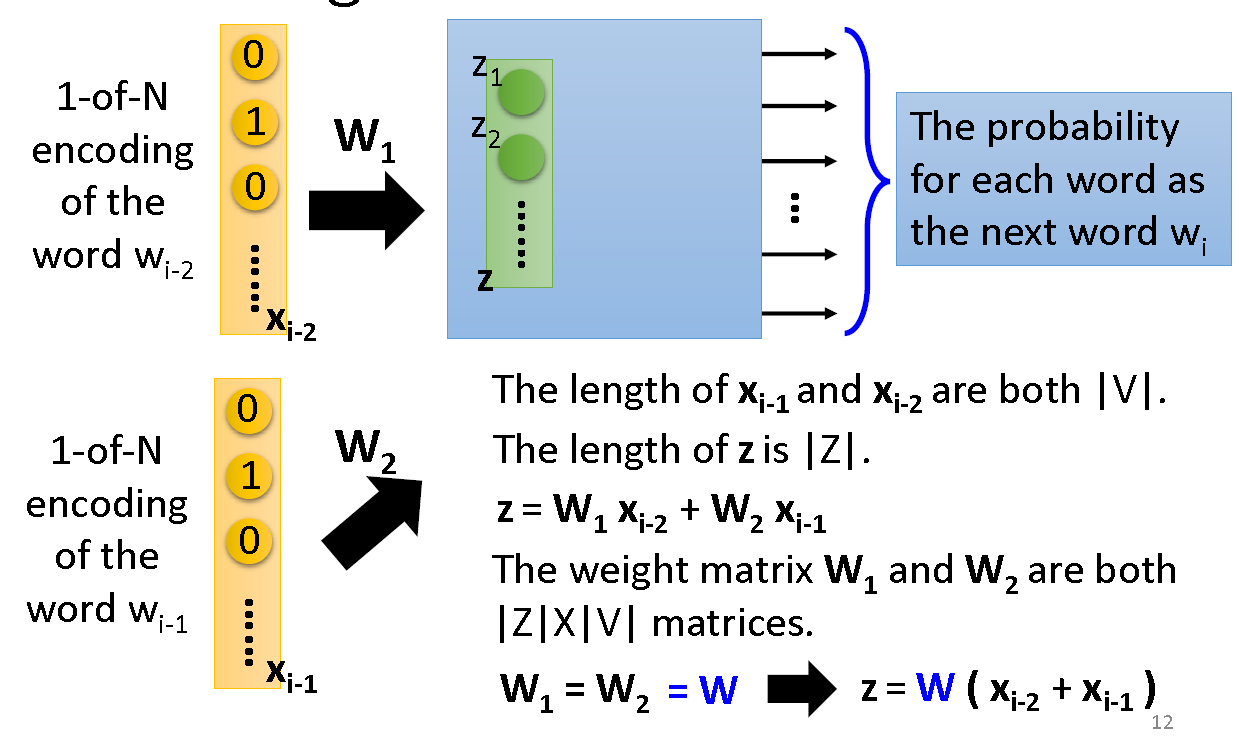
训练的目的是,得到hidden layer的映射,就是该词汇新的向量表示,(其实感觉和自编码器很像对不对!

CBOW(continuous bag of word),根据上下文猜中间词
Skip-grams,通过中间词猜上下文
seq2seq
Conditional、Attention-based
看这篇就够了,太强了完全图解RNN、RNN变体、Seq2Seq、Attention机制 - 何之源的文章 - 知乎
简单来说,普通的映射就是f(x)=y,但是为了在NLP里用到上下文的信息,需要带有结构的输入,就是RNN或LSTM,
最经典的RNN就是,输入与输出N vs N的,引入隐状态h(hidden state),h可以对序列形的数据提取特征,接着再转换为输出。
下图的意思就是通过h0和x1生成h1,在通过h1生成y1,接着再通过h1和x2生成h2,
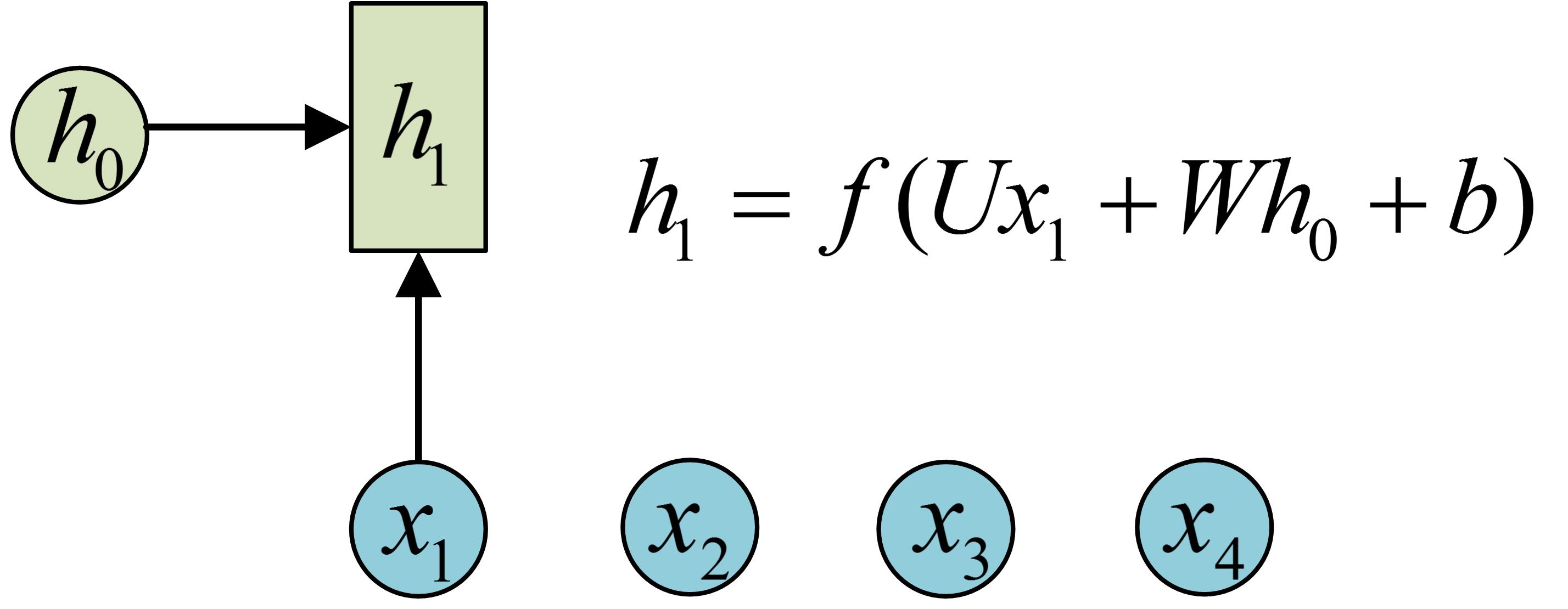
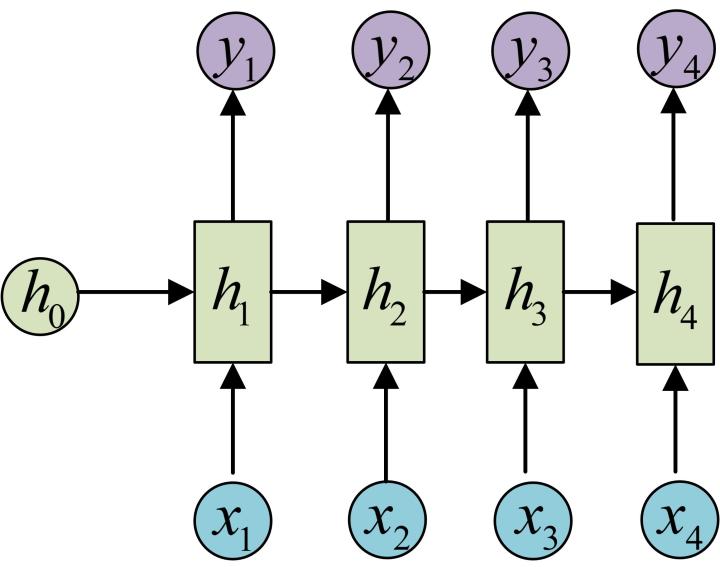
而Seq2seq,就是N vs M,这种结构又叫Encoder-Decoder模型,也可以称之为Seq2Seq模型。
原始的N vs N RNN要求序列等长,然而我们遇到的大部分问题序列都是不等长的,如机器翻译中,源语言和目标语言的句子往往并没有相同的长度。
为此,Encoder-Decoder结构先将输入数据编码成一个上下文向量c:
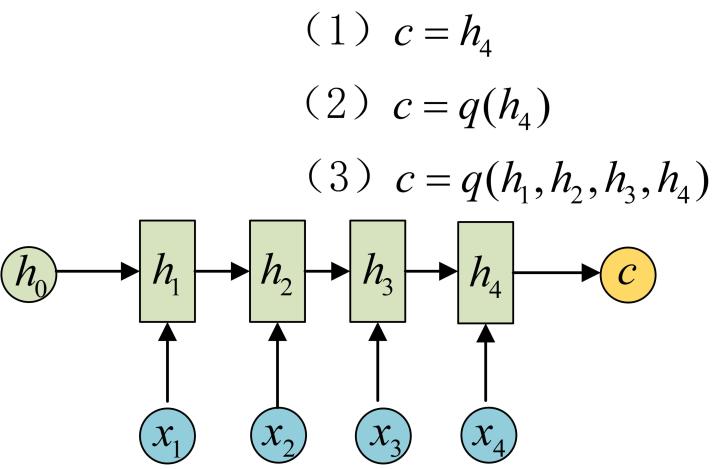
得到c有多种方式,最简单的方法就是把Encoder的最后一个隐状态赋值给c,还可以对最后的隐状态做一个变换得到c,也可以对所有的隐状态做变换。
拿到c之后,就用另一个RNN网络对其进行解码,这部分RNN网络被称为Decoder。具体做法就是将c当做之前的初始状态h0输入到Decoder中:
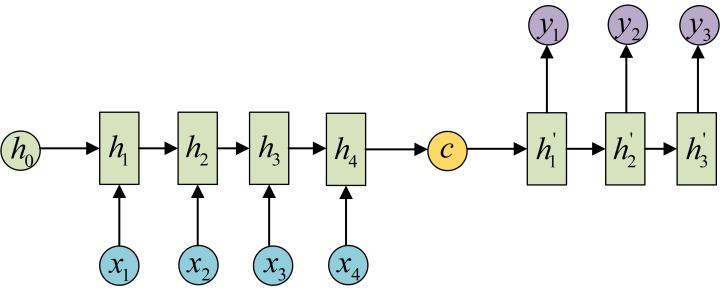
还有一种做法是将c当做每一步的输入:
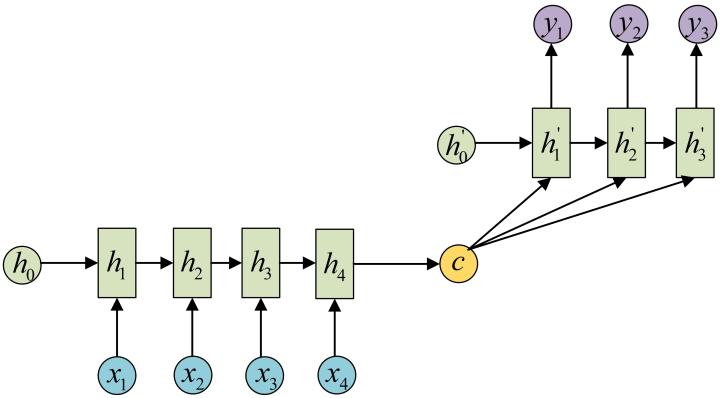
由于这种Encoder-Decoder结构不限制输入和输出的序列长度,因此应用的范围非常广泛,比如:
- 机器翻译。Encoder-Decoder的最经典应用,事实上这一结构就是在机器翻译领域最先提出的
- 文本摘要。输入是一段文本序列,输出是这段文本序列的摘要序列。
- 阅读理解。将输入的文章和问题分别编码,再对其进行解码得到问题的答案。
- 语音识别。输入是语音信号序列,输出是文字序列。
- …………
Attention
Attention其实就是conditional的seq2seq
在Encoder-Decoder结构中,Encoder把所有的输入序列都编码成一个统一的语义特征c再解码,因此, c中必须包含原始序列中的所有信息,它的长度就成了限制模型性能的瓶颈。如机器翻译问题,当要翻译的句子较长时,一个c可能存不下那么多信息,就会造成翻译精度的下降。
Attention机制通过在每个时间输入不同的c来解决这个问题,下图是带有Attention机制的Decoder:
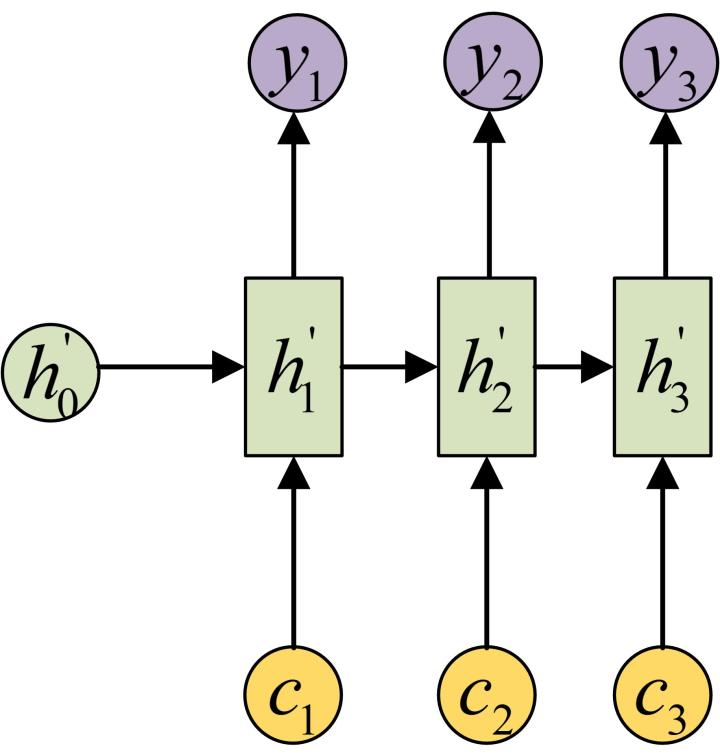
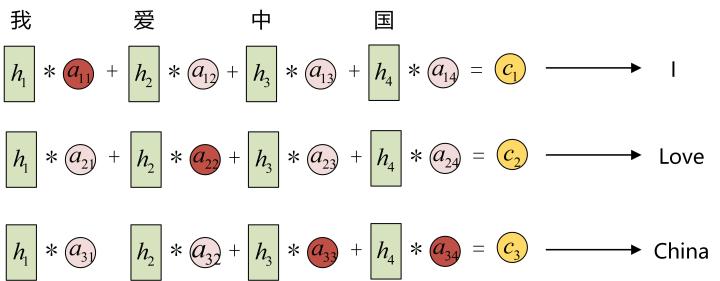
每一个c会自动去选取与当前所要输出的y最合适的上下文信息。具体来说,我们用aij衡量Encoder中第j阶段的hj和解码时第i阶段的相关性,最终Decoder中第i阶段的输入的上下文信息ci就来自于所有hj对aij的加权和。
以机器翻译为例(将中文翻译成英文):
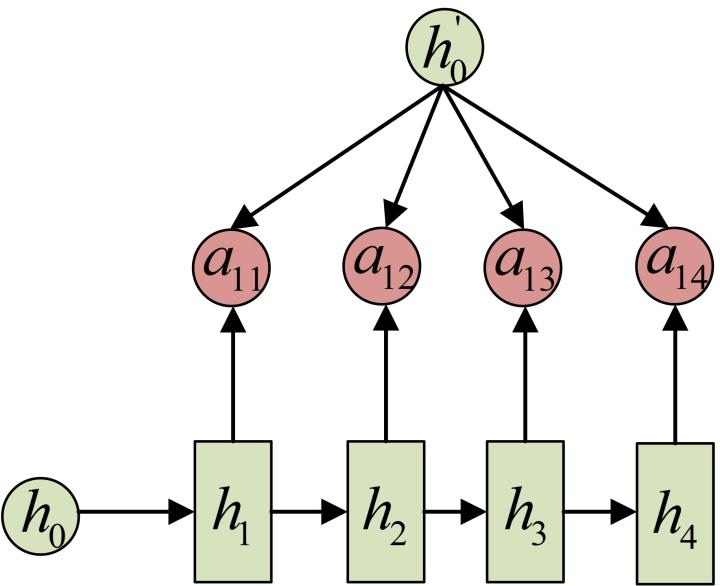
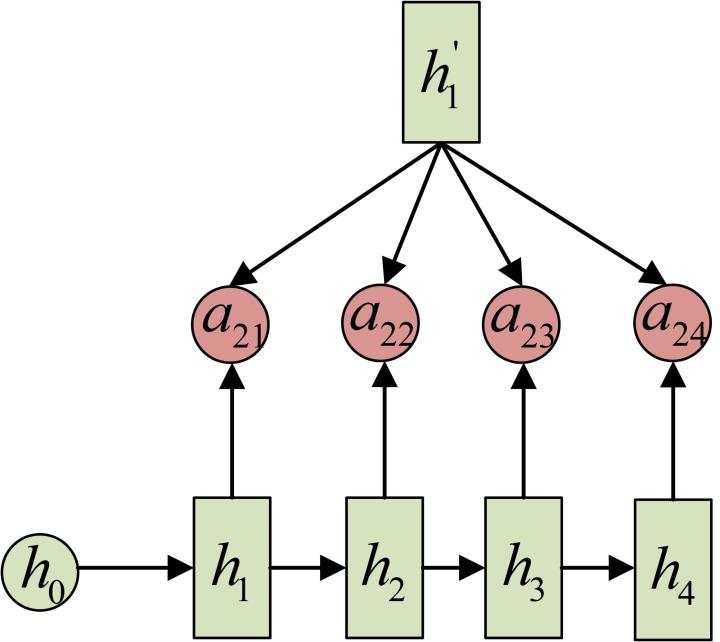
Transformer
详解Transformer (Attention Is All You Need) - 大师兄的文章 - 知乎 https://zhuanlan.zhihu.com/p/48508221
BERT
模型的演变:
从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 - 张俊林的文章 - 知乎 https://zhuanlan.zhihu.com/p/49271699
模型的改进:
NLP:NLP领域没有最强,只有更强的模型——GPT-3的简介、安装、使用方法之详细攻略
GPT
NER
命名实体识别(Named Entity Recognition,简称NER),是信息提取、问答系统、句法分析、机器翻译等应用领域的重要基础工具,一般来说,命名实体识别的任务就是识别出待处理文本中三大类(实体类、时间类和数字类)、七小类(人名、机构名、地名、时间、日期、货币和百分比)命名实体。
中文实体抽取(NER)论文笔记《Chinese NER Using Lattice LSTM》
分词
文本分类
用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践
Some blogs and papers
重要但是还未有空细细琢磨的,之后有空再看一遍
NER中的词汇增强方法(LatticeLSTM、CGN、FLAT、Simple-Lexicon)
自然语言处理(NLP)语义分析—文本分类、情感分析、意图识别
深度学习中的注意力模型(2017版) - 张俊林的文章 - 知乎 https://zhuanlan.zhihu.com/p/37601161
从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 - 张俊林的文章 - 知乎 https://zhuanlan.zhihu.com/p/49271699
GPT3原文: Language Models are Few-Shot Learners
Bert原文:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding