看得再多,不如踏实干,而踏实码起代码,跑起模型,还是要做到心里有数,有的放矢
老说DL是炼丹,但是还是有一些需要注意的,其实以前看过好多相关的知识点了,但还是需要串起来、记下来好好思考
不全也不一定对,但是慢慢整理慢慢补吧~
欲炼灵丹,先备好料?
构建数据集
一般可将ML分为监督学习与无监督学习,当然还有半监督学习,当前很火的自监督学习等,当从前期准备上来说,就看数据集是否有和我们训练目标相对应的label,能否显性地指明样本属于的类别,如果可以就要组成pair-wise的data-label对,否则就是单纯的data point
留坑整理:机器学习、深度学习、监督学习、无监督学习、半监督学习、自监督学习、强化学习、迁移学习、元学习等各类学习,
已有部分:some basic knowledge of DL,Few-shot Learning and Meta-Learning
训练集/验证集/测试集
那么得到dataset后,就能够对模型进行训练以学习得到分类或其他能力,但是为了之后验证辨别能力的真正效果,在训练之前,还需要对所有的数据作切分,大致分为训练集(training set),验证集(validation set)和测试集(test set)
简单来说,训练集是用于训练模型的,或者换句话说,其实就是用于评估当前模型权重是否适合,指导权重的更新,
验证集是用于评估当前模型整体性能的,针对的是权重已训练到极限后,对模型结构等超参数的评估,从而指导超参数的选取,
最后的测试集才是最终评价模型性能的
三者不能有交集,因为后者都是用于评估前者的,如果有交集,那么就使得前述的环节接触到了后续评估的标准,可能由“过拟合”导致虚假的性能评价
其实在验证集之外还有测试集的目的,就在于使其最后评价出来的最优模型是无偏(unbias)的,这个我觉得wiki写的很好:
但事实上,很多时候为了方便,一般只分成训练集和验证集
详情可继续参考之前的博客:训练集&验证机&测试集
交叉检验
前文提到的讲数据集分成不交叉的训练集、验证集、测试集,可以认为是holdout检验,而目前的主流检验方式还包括交叉验证(Cross Validation),有的时候也称作循环估计(Rotation Estimation),是一种统计学上将数据样本切割成较小子集的实用方法,该理论是由Seymour Geisser提出的,其实核心思想就是训练集和测试集并不是一成不变的,可能存在身份互换,从而交叉地检验模型
厘一下关系,交叉检验是思想,留一法等是具体方法
彻底的交叉验证(Exhaustive Cross Validation)
彻底的交叉验证方法指的是遍历全集X的所有非空真子集A。换句话说也就是把A当作训练集,X\A是测试集。如果X中有n个元素,那么非空真子集A的选择方法则是2^{n}-2,这个方法的时间复杂度是指数级别的。
留P验证(Leave-p-out Cross Validation)
留p验证(LpO CV)指的是使用全集X中的p个元素作为测试集,然后剩下的n-p个元素作为训练集。根据数学上的定理可以得到,p个元素的选择方法有n!/((n-p)!p!)个,其中n!表示n的阶乘。在这个意义下,留p验证的时间复杂度也是非常高的。当p=1的时候,留1验证(Leave-one-out Cross Validation)的复杂度恰好是n。
k-fold交叉验证(K-fold Cross Validation)
在k-fold交叉验证中,全集X被随机的划分成k个同等大小的集合A1,…,Ak,并且|A1|=…=|Ak|。这里的|Ai|指的是集合Ai的元素个数,也就是集合的势。这个时候需要遍历i从1到k,把X\Ai当作训练集合,Ai当作测试集合。根据模型的测试统计,可以得到Ai集合中测试错误的结果数量ni。如果全集X的势是n的话,可以得到该模型的错误率是E=(ni求和)/n.
为了提高模型的精确度,可以将k-fold交叉验证的上述步骤重复t次,每一次都是随机划分全集X。在t次测试中,会得到t个模型的错误率E1,…,Et。令e=(Ei求和)/t。这样该模型的错误率就是e。
当k=2的时候,也就是最简单的k-fold交叉验证,2-fold交叉验证。这个时候X是A1和A2**的并集,首先A1当训练集并且A2当测试集,然后A2当训练集并且A1当测试集。2-fold交叉验证的好处就是训练集和测试集的势都非常大,每个数据要么在训练集中,要么在测试集中。
当k=n的时候,也就是n-fold交叉验证。这个时候就是上面所说的留一验证(Leave-one-out Cross Validation,LOOCV)
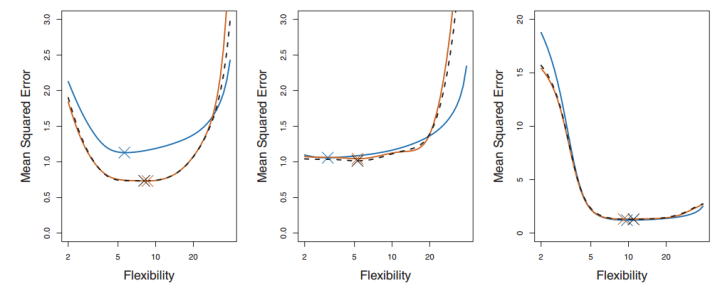
每一幅图种蓝色表示的真实的test MSE,而黑色虚线和橙线则分贝表示的是LOOCV方法和10-fold CV方法得到的test MSE。我们可以看到事实上LOOCV和10-fold CV对test MSE的估计是很相似的,但是相比LOOCV,10-fold CV的计算成本却小了很多,耗时更少。
K的选取
最后,我们要说说K的选取。事实上,和开头给出的文章里的部分内容一样,K的选取是一个Bias和Variance的trade-off。
K越大,每次投入的训练集的数据越多,模型的Bias越小。但是K越大,又意味着每一次选取的训练集之前的相关性越大(考虑最极端的例子,当k=N,也就是在LOOCV里,每次都训练数据几乎是一样的)。而这种大相关性会导致最终的test error具有更大的Variance。
参考:交叉验证(Cross Validation)简介, 【机器学习】Cross-Validation(交叉验证)详解
通过Pytorch构建数据集
留坑最近填:在pytorch中载入数据集并构建训练集、验证集
tranform介绍:Pytorch:transforms的二十二个方法
Pytorch:transforms二十二种数据预处理方法及自定义transforms方法
去芜存菁,万事俱备
数据预处理(Data Preprocessing)
之前的博客:归一化、标准化、中心化
数据增强(Data Augmentation)
数据增强,通过让有限的数据产生更多的等价数据来人工扩展训练数据集的技术,是克服训练数据不足的有效手段。
计算机视觉
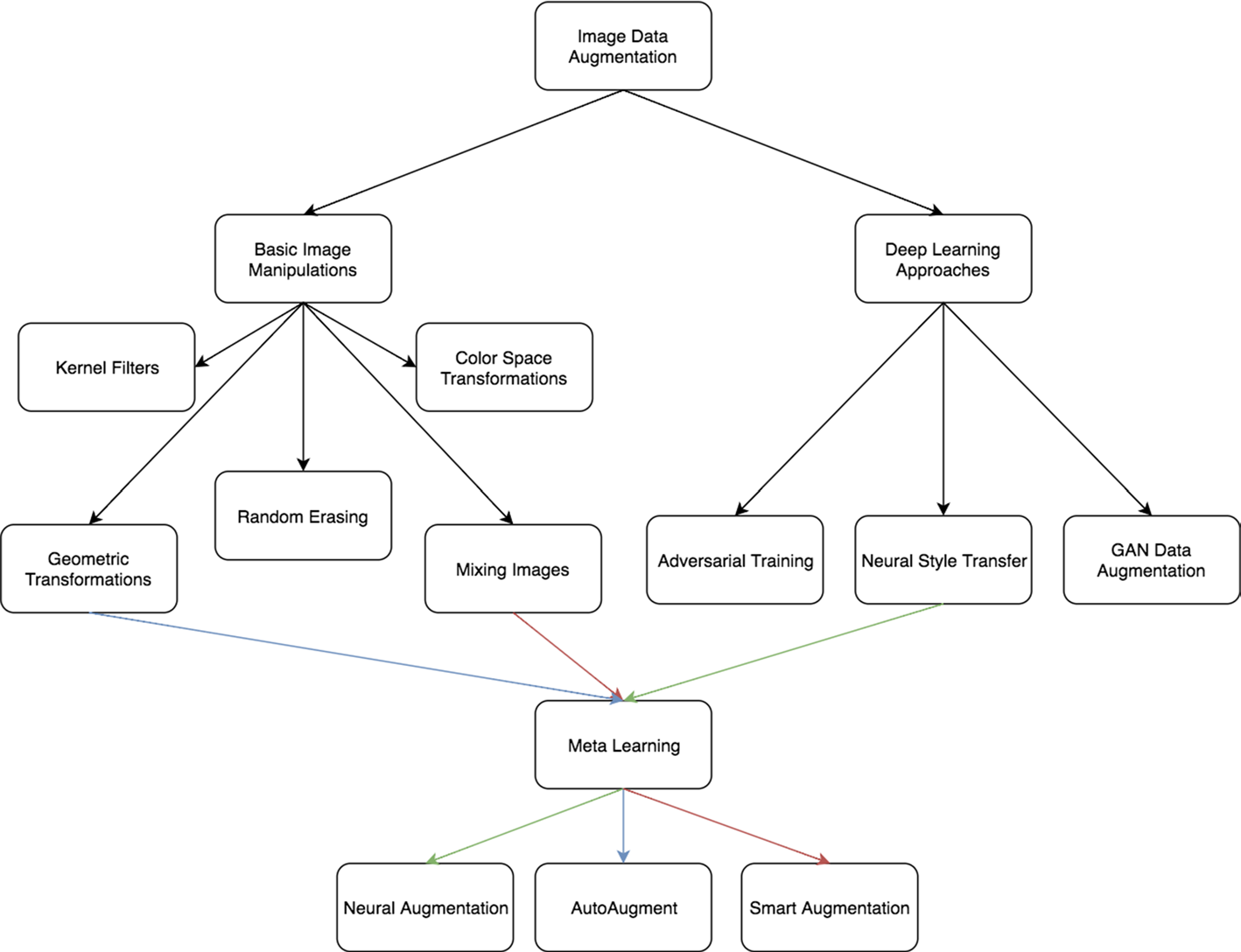
CV的数据增强算法大致可以分为两类:第一类是基于基本图像处理技术的数据增强,第二个类别是基于深度学习的数据增强算法。
下面先介绍基于基本图像处理技术的数据增强方法:
基本的图像处理(basic image manipulations)
几何变换(Geometric Transformations):由于训练集与测试集合中可能存在潜在的位置偏差,使得模型在测试集中很难达到训练集中的效果,几何变换可以有效地克服训练数据中存在的位置偏差,而且易于实现,许多图像处理库都包含这个功能。
当然也需要注意几何变换后能否保留相应的标签信息,对于ImageNet中的猫狗识别没问题,但是MNIST中的6和9数字识别就有风险了翻转变换(Flipping):通常是关于水平或者竖直的轴进行图像翻转操作,这种扩充是最容易实现的扩充,并且已经证明对ImageNet数据集有效。
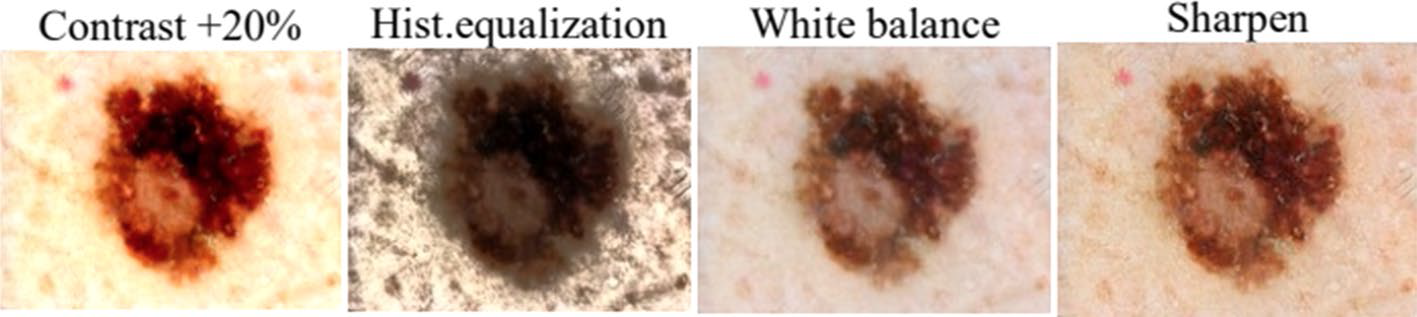
颜色变换(Color Space):图片在输入计算机之前,通常会被编码为张量(高度×宽度×颜色通道),所以可以在色彩通道空间进行数据增强,比如将某种颜色通道关闭,或者改变亮度值。
裁剪(Cropping):如果输入数据集合的大小是变化的,裁剪可以作为数据预处理的一个手段,通过裁剪图像的中央色块,可以得到新的数据。在实际使用过程之中,这些数据增强算法不是只使用一种,而是使用一套数据增强策略,在AutoAugment这篇文章中,作者尝试让模型自动选择数据增强策略。
旋转 | 反射变换(Rotation/Reflection):选择一个角度,左右旋转图像,可以改变图像内容朝向。关于旋转角度需要慎重考虑,角度太大或者太小都不合适,适宜的角度是1度 到 20度。
移动(Translation):向左,向右,向上或向下移动图像可以避免数据中的位置偏差,比如在人脸识别数据集合中,如果所有图像都居中,使用这种数据增强方法可以避免可能出现的位置偏差导致的错误。
噪声注入(Noise Injection):从高斯分布中采样出的随机值矩阵加入到图像的RGB像素中,通过向图像添加噪点可以帮助CNN学习更强大的功能。
颜色空间变换(color space transformation):

缩放变换(Zoom):图像按照一定的比例进行放大和缩小并不改变图像中的内容,可以增加模型的泛化性能。
几何与光度转换(Geometric versus photometric transformations)
- 内核过滤器(Kernel Filters):内核滤镜是在图像处理中一种非常流行的技术,比如锐化和模糊。将特定功能的内核滤镜与图像进行卷积操作,就可以得到增强后的数据。直观上,数据增强生成的图像可能会使得模型面对这种类型的图像具有更高的鲁棒性。
- 混合图像(Mix):通过平均图像像素值将图像混合在一起是一种非常违反直觉的数据增强方法。对于人来说,混合图像生成的数据似乎没有意义。虽然这种方法缺乏可解释性,但是作为一种简单有效的数据增强算法,有一系列的工作进行相关的研究。Inoue在图像每个像素点混合像素值来混合图像,Summers和Dinneen又尝试以非线性的方法来混合图像,Takahashi和Matsubara通过随机图像裁剪和拼接来混合图像,以及后来的mixup方法均取得了不错的成果。
- 随机擦除(Random Erasing):随机擦除是Zhong等人开发的数据增强技术。他们受到Dropout机制的启发,随机选取图片中的一部分,将这部分图片删除,这项技术可以提高模型在图片被部分遮挡的情况下性能,除此之外还可以确保网络关注整个图像,而不只是其中的一部分。
基于深度学习(Based on Deep Learning):
- 特征空间增强(Feature Space Augmentation):神经网络可以将图像这种高维向量映射为低维向量,之前讨论的所有图像数据增强方法都应用于输入空间中的图像。现在可以在特征空间进行数据增强操作,例如:SMOTE算法,它是一种流行的增强方法,通过将k个最近的邻居合并以形成新实例来缓解类不平衡问题。
- 对抗生成(Adversarial Training):对抗攻击表明,图像表示的健壮性远不及预期的健壮性,Moosavi-Dezfooli等人充分证明了这一点。对抗生成可以改善学习的决策边界中的薄弱环节,提高模型的鲁棒性。
- 基于GAN的数据增强(GAN-based Data Augmentation):使用 GAN 生成模型来生成更多的数据,可用作解决类别不平衡问题的过采样技术。
- 神经风格转换(Neural Style Transfer):通过神经网络风格迁移来生成不同风格的数据,防止模型过拟合。
- 元学习(Meta Learning)
如果想要阅读更多的细节,请参考这篇文章:A survey on Image Data Augmentation for Deep Learning
自然语言处理
在自然语言处理领域,被验证为有效的数据增强算法相对要少很多,下面我们介绍几种常见方法。
同义词词典(Thesaurus):Zhang Xiang等人提出了Character-level Convolutional Networks for Text Classification,通过实验,他们发现可以将单词替换为它的同义词进行数据增强,这种同义词替换的方法可以在很短的时间内生成大量的数据。
随机插入(Randomly Insert):随机选择一个单词,选择它的一个同义词,插入原句子中的随机位置,举一个例子:“我爱中国” —> “喜欢我爱中国”。
随机交换(Randomly Swap):随机选择一对单词,交换位置。
随机删除(Randomly Delete):随机删除句子中的单词。
语法树结构替换:通过语法树结构,精准地替换单词。
加噪(NoiseMix) (https://github.com/noisemix/noisemix):类似于图像领域的加噪,NoiseMix提供9种单词级别和2种句子级别的扰动来生成更多的句子,例如:这是一本很棒的书,但是他们的运送太慢了。->这是本很棒的书,但是运送太慢了。
情境增强(Contextual Augmentation):这种数据增强算法是用于文本分类任务的独立于域的数据扩充。通过用标签条件的双向语言模型预测的其他单词替换单词,可以增强监督数据集中的文本。
生成对抗网络:利用生成对抗网络的方法来生成和原数据同分布的数据,来制造更多的数据。在自然语言处理领域,有很多关于生成对抗网络的工作:
- Generating Text via Adversarial Training
- GANS for Sequences of Discrete Elements with the Gumbel-softmax Distribution
- SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient
回译技术(Back Translation):回译技术是NLP在机器翻译中经常使用的一个数据增强的方法。其本质就是快速产生一些翻译结果达到增加数据的目的。回译的方法可以增加文本数据的多样性,相比替换词来说,有时可以改变句法结构等,并保留语义信息。但是,回译的方法产生的数据严重依赖于翻译的质量。
扩句-缩句-句法:先将句子压缩,得到句子的缩写,然后再扩写,通过这种方法生成的句子和原句子具有相似的结构,但是可能会带来语义信息的损失。
无监督数据扩增(Unsupervised Data Augmentation):通常的数据增强算法都是为有监督任务服务,这个方法是针对无监督学习任务进行数据增强的算法,UDA方法生成无监督数据与原始无监督数据具备分布的一致性,而以前的方法通常只是应用高斯噪声和Dropout噪声(无法保证一致性)。(https://arxiv.org/abs/1904.12848)
还可以了解一下:池化的作用,CNN的平移不变性、旋转不变性
主要参考自:深度学习领域的数据增强
数据平衡
看料搭炉,拾柴点火
模型选取
问题特点,模型特点,大坑,慢填
网络搭建
超参数和常用方法的概念,最后一章是具体的结合分析
之前的博客:激活函数探究,Batch Normalization,梯度消失、爆炸与其解决方案,池化的作用,正则化作用及其推导
PyTorch 学习笔记(八):PyTorch的六个学习率调整方法
巧借东风,百炼成丹
训练技巧——快
调参技巧——准
深度学习网络调参技巧 - 萧瑟的文章 - 知乎 https://zhuanlan.zhihu.com/p/24720954
贝叶斯优化: 一种更好的超参数调优方式 - tobe的文章 - 知乎 https://zhuanlan.zhihu.com/p/29779000
深度学习网络训练技巧汇总 - 萧瑟的文章 - 知乎 https://zhuanlan.zhihu.com/p/20767428
深度学习网络调试技巧 - 萧瑟的文章 - 知乎 https://zhuanlan.zhihu.com/p/20792837
优化函数
最常用的:Adam和SGD-M
经典的三个博客:
一个框架看懂优化算法之异同 SGD/AdaGrad/Adam - Juliuszh的文章 - 知乎 https://zhuanlan.zhihu.com/p/32230623
Adam那么棒,为什么还对SGD念念不忘 (2)—— Adam的两宗罪 - Juliuszh的文章 - 知乎 https://zhuanlan.zhihu.com/p/32262540
Adam那么棒,为什么还对SGD念念不忘 (3)—— 优化算法的选择与使用策略 - Juliuszh的文章 - 知乎 https://zhuanlan.zhihu.com/p/32338983
李宏毅老师的PPT Optimization of DNN

都9102年了,别再用Adam + L2 regularization了 - paperplanet的文章 - 知乎 https://zhuanlan.zhihu.com/p/63982470
(“所以应该先Adam with weight decay=0,然后sgd with l2 regularization,赞”—— frey Wang)