卷积神经网络,作为最热门的机器视觉模型之一,具有很强的识别能力,但其本身有很多细节需要掌握
当然,还是要感谢各位先贤能够想出这么多厉害的idea,同样感谢各位愿意分享自己见解,让我们更好理解到只是的传道者们,感谢Internet!
建议阅读
卷积神经网络结构演变(form Hubel and Wiesel to SENet)——学习总结,文末附参考论文 梳理的特别好,从60年代,神经网络提出到,Lecun的LeNet,再到AlexNet,以及之后的各种网络,而且归类的特别好,看历史发展看这篇就够了,然后有看不懂和感兴趣的,自己再去查就好,真的真的非常感谢!
深入浅出卷积神经网络及实现 对各个模型讲解的比较细致,同样非常感谢和推荐
LeNet5
1998年,继1989年Lecun第一次提出三层神经网络训练邮政数字训练之后,通过9年的积累,第一次提出了卷积网络(Convolution Network)的概念,并且把结果同各种方法做了一个比较,基本唯一能抗衡的就是V-SVM poly9,结果祭出大杀器Boost,Boosted LeNet-4,以0.1%的优势干掉了SVM。
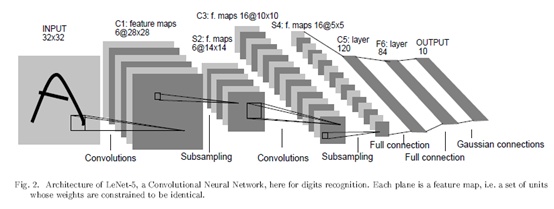
此时就明确了卷积、池化、参数共享等操作,避免了大量的计算成本,最后再使用全连接神经网络进行分类识别,这个网络也是最近大量神经网络架构的起点。
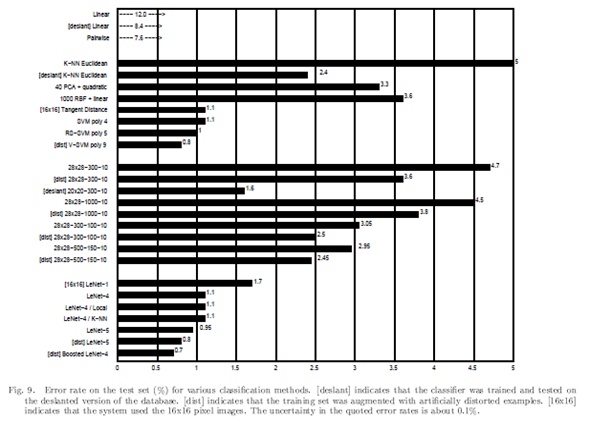
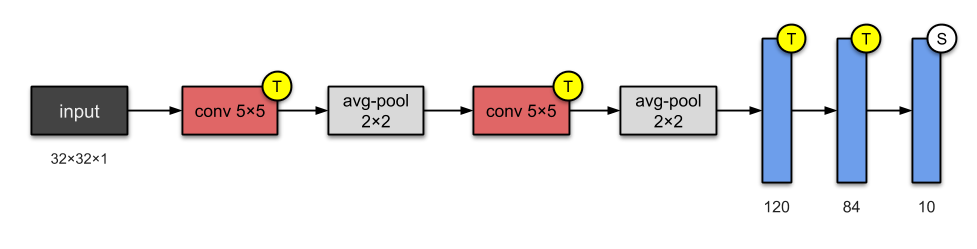
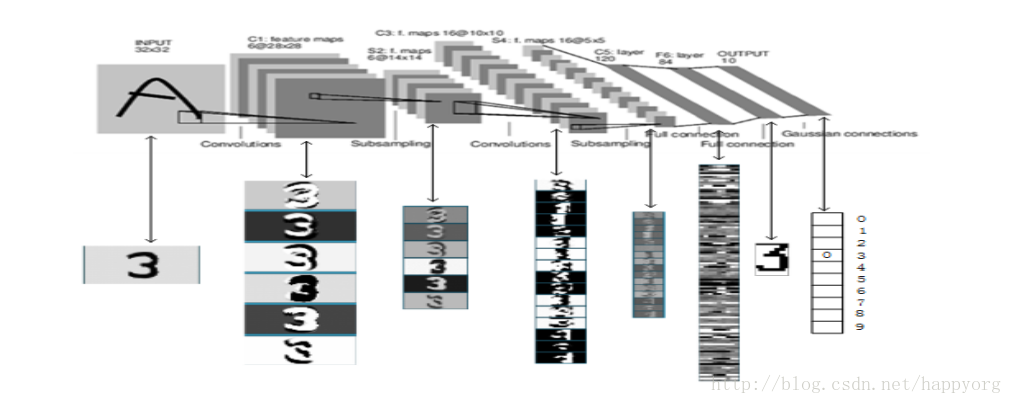
LeCun在这篇论文里面非常详细的介绍了自己的工作,看看网络结构,就是经典的卷积、池化(或叫降采样),最后是全连接层
这项工作一出来,的确在当时引起了不小的轰动,LeCun也准备大展拳脚,可惜啊,接下来出现了一些表现更好的手工设计的特征比如:SIFT,HOG,LBP这些算子再加上SVM,原理的清晰性,模型可解释,数据需求小,计算需求小,很快盖过了LeCun的工作,他也为此郁闷了15年。
AlexNet
让深度学习重新火热起来的,是Alex Krizhevsky提出的AlexNet,此时采用了8层神经网络卷积神经网络和多种trick,如dropput,relu,学习率衰减等,
.png)
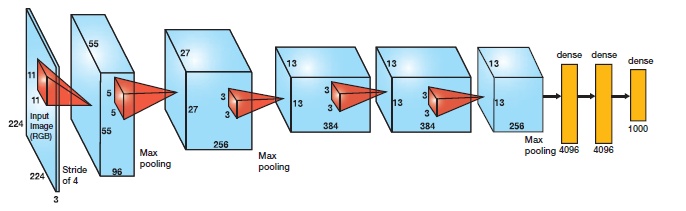
与相对较小的LeNet相比,AlexNet包含8层变换,其中有5层卷积和2层全连接隐藏层,以及1个全连接输出层。下面我们来详细描述这些层的设计:AlexNet第一层中的卷积窗口形状是11x11。因为ImageNet中绝大多数图像的高和宽均比MNIST图像的高和宽大10倍以上,ImageNet图像的物体占用更多的像素,所以需要更大的卷积窗口来捕获物体。第二层中的卷积窗口形状减小到5x5,之后全采用3x3。此外,第一、第二和第五个卷积层之后都使用了窗口形状为3x3、步幅为2的最大池化层。而且,AlexNet使用的卷积通道数也大于LeNet中的卷积通道数数十倍。紧接着最后一个卷积层的是两个输出个数为4096的全连接层。这两个巨大的全连接层带来将近1 GB的模型参数。由于早期显存的限制,最早的AlexNet使用双数据流的设计使一个GPU只需要处理一半模型。幸运的是,显存在过去几年得到了长足的发展,因此通常我们不再需要这样的特别设计了。
AlexNet将sigmoid激活函数改成了更加简单的ReLU激活函数。一方面,ReLU激活函数的计算更简单,例如它并没有sigmoid激活函数中的求幂运算。另一方面,ReLU激活函数在不同的参数初始化方法下使模型更容易训练。这是由于当sigmoid激活函数输出极接近0或1时,这些区域的梯度几乎为0,从而造成反向传播无法继续更新部分模型参数;而ReLU激活函数在正区间的梯度恒为1。因此,若模型参数初始化不当,sigmoid函数可能在正区间得到几乎为0的梯度,从而令模型无法得到有效训练。
AlexNet通过dropout来控制全连接层的模型复杂度。而LeNet并没有使用dropout。
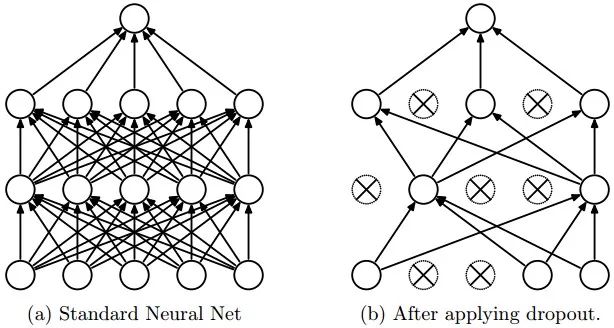
AlexNet引入了大量的图像增广,如翻转、裁剪和颜色变化,从而进一步扩大数据集来缓解过拟合。我们将在后面的图像增广中详细介绍这种方法。
小结:
- AlexNet跟LeNet结构类似,但使用了更多的卷积层和更大的参数空间来拟合大规模数据集ImageNet。它是浅层神经网络和深度神经网络的分界线。
- 虽然看上去AlexNet的实现比LeNet的实现也就多了几行代码而已,但这个观念上的转变和真正优秀实验结果的产生令学术界付出了很多年。
- ReLu和Dropout等技巧
VGG-16
AlexNet在LeNet的基础上增加了3个卷积层。但AlexNet作者对它们的卷积窗口、输出通道数和构造顺序均做了大量的调整。
虽然AlexNet指明了深度卷积神经网络可以取得出色的结果,但并没有提供简单的规则以指导后来的研究者如何设计新的网络。
VGG,它的名字来源于论文作者所在的实验室Visual Geometry Group。VGG提出了可以通过重复使用简单的基础块来构建深度模型的思路。VGG的结构图如下:
.png)
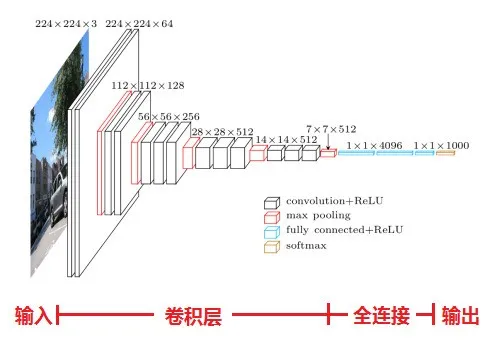
VGG块的组成规律是:连续使用数个相同的填充为1、窗口形状为3x3的卷积层后接上一个步幅为2、窗口形状为2x2的最大池化层。卷积层保持输入的高和宽不变,而池化层则对其减半。我们使用vgg_block函数来实现这个基础的VGG块,它可以指定卷积层的数量和输入输出通道数。
对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核优于采用大的卷积核,因为可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。例如,在VGG中,使用了3个3x3卷积核来代替7x7卷积核,使用了2个3x3卷积核来代替5*5卷积核,这样做的主要目的是在保证具有相同感知野的条件下,提升了网络的深度,在一定程度上提升了神经网络的效果。
与AlexNet和LeNet一样,VGG网络由卷积层模块后接全连接层模块构成。卷积层模块串联数个vgg_block,其超参数由变量conv_arch定义。该变量指定了每个VGG块里卷积层个数和输入输出通道数。全连接模块则跟AlexNet中的一样。
现在我们构造一个VGG网络。它有5个卷积块,前2块使用单卷积层,而后3块使用双卷积层。第一块的输入输出通道分别是1(因为下面要使用的Fashion-MNIST数据的通道数为1)和64,之后每次对输出通道数翻倍,直到变为512。因为这个网络使用了8个卷积层和3个全连接层,所以经常被称为VGG-11。
可以看到,每次我们将输入的高和宽减半,直到最终高和宽变成7后传入全连接层。与此同时,输出通道数每次翻倍,直到变成512。因为每个卷积层的窗口大小一样,所以每层的模型参数尺寸和计算复杂度与输入高、输入宽、输入通道数和输出通道数的乘积成正比。VGG这种高和宽减半以及通道翻倍的设计使得多数卷积层都有相同的模型参数尺寸和计算复杂度。
VGG:通过重复使⽤简单的基础块来构建深度模型。 Block: 数个相同的填充为1、窗口形状为3×3的卷积层,接上一个步幅为2、窗口形状为2×2的最大池化层。卷积层保持输入的高和宽不变,而池化层则对其减半。VGG和AlexNet的网络图对比如下:
.png)
小结:
VGG-11通过5个可以重复使用的卷积块来构造网络。根据每块里卷积层个数和输出通道数的不同可以定义出不同的VGG模型。
常用的还有VGG-16、VGG-19
与AlexNet相比,VGG-Net拥有更小的卷积核和更深的层级
VGG-Net 的泛化性能非常好,常用于图像特征的抽取目标检测候选框生成等。VGG 最大的问题就在于参数数量,VGG-19 基本上是参数量最多的卷积网络架构。
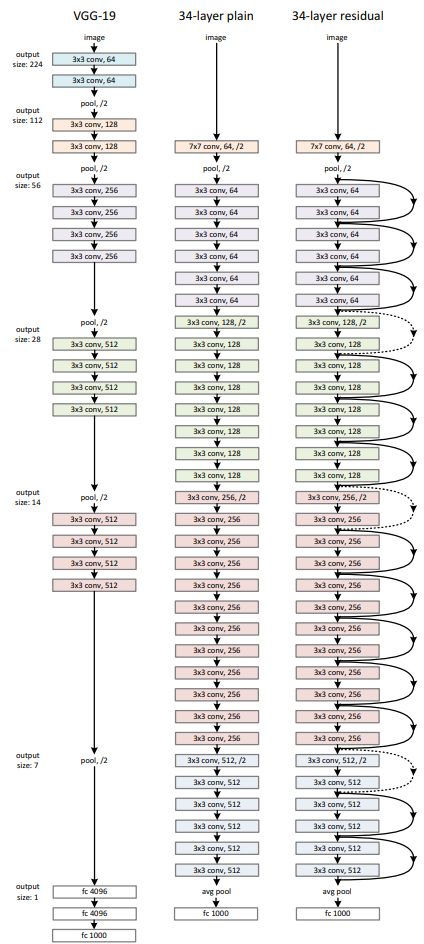
ResNet
推荐阅读
薰风读论文:Deep Residual Learning 手把手带你理解ResNet
当CNN的层次变深,效果却下降,通过分析:
1、不是过拟合,因为训练误差和测试误差都很大
2、不是梯度爆炸/弥散,因为该问题已经基本被BN解决了
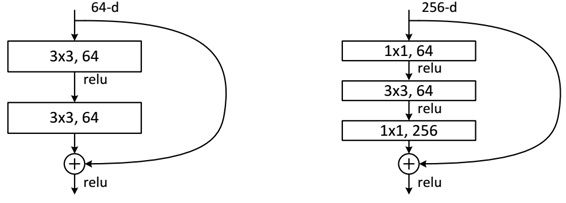
而ResNet提出的初心也很简单,层次变深,哪怕啥效果都没有,起码不会变差吧,于是何恺明博士提出了恒等变换,就是后面的层次没啥用,
H(x) = x就好,同时,H(x)这样的恒等变换不好直接找,那么我们去找他的残差,F(x)=H(x)-x,该层学习的是F(x),x直接短路传到该层的output,
其结构如下,左右的区别在于,经过卷积,数据的维度可能改变了,所以:
(1)采用zero-padding增加维度,此时一般要先做一个downsamp,可以采用strde=2的pooling,这样不会增加参数;
(2)采用新的映射(projection shortcut),一般采用1x1的卷积,这样会增加参数,也会增加计算量。
.png)
那么,ResNet到底发现并解决了啥问题呢?
看了几个回答,说其实解决的不是overfitting or gradient explode/vanish,解决的是模型的退化问题,参考Resnet到底在解决一个什么问题呢?中王峰老师的回答:
今年2月份有篇文章,正好跟这个问题一样。
The Shattered Gradients Problem: If resnets are the answer, then what is the question?
大意是神经网络越来越深的时候,反传回来的梯度之间的相关性会越来越差,最后接近白噪声。因为我们知道图像是具备局部相关性的,那其实可以认为梯度也应该具备类似的相关性,这样更新的梯度才有意义,如果梯度接近白噪声,那梯度更新可能根本就是在做随机扰动。
有了梯度相关性这个指标之后,作者分析了一系列的结构和激活函数,发现resnet在保持梯度相关性方面很优秀这一点其实也很好理解,从梯度流来看,有一路梯度是保持原样不动地往回传,这部分的相关性是非常强的。
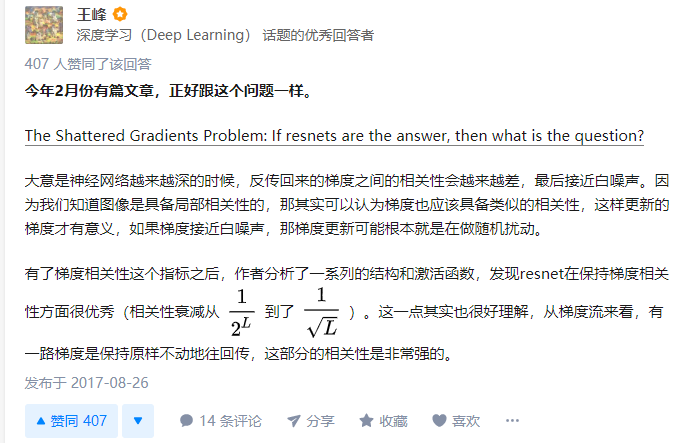
论文[4]认为,即使BN过后梯度的模稳定在了正常范围内,但梯度的相关性实际上是随着层数增加持续衰减的。而经过证明,ResNet可以有效减少这种相关性的衰减。
([4]Balduzzi D , Frean M , Leary L , et al. The Shattered Gradients Problem: If resnets are the answer, then what is the question?[J]. 2017.)
ResNet的结构:
DenseNet
ResNet通过将上一层的结果直接跳接到本层的输出,实现了比较好的结果,而DenseNet的尝试就是,神经网络其实并不一定要是一个递进层级结构,也就是网络中的某一层并不仅仅依赖紧邻的上一层特征,而可以依赖于前面某一层的特征信息,所以他的思路就是,让网络的每一层与自己之前的所有蹭都连接,实现特征的重复利用
这篇文章是CVPR2017的BestPaper,整篇文章的思路就是把每一层都与其他所有层连接起来,思路很简单,效果很棒!这篇文章当时好像投了三次,都没中,结果投CVPR却中了,还拿了一个BestPaper。我想绝大部分人看到这篇文章的时候都是:我擦,这也可以吗?根据作者的解释说他们之前提出过一个随机深度网络来改善ResNet,也就是随机丢掉一些层,发现可以显著提升泛化性能。这个实验启发他们:神经网络其实并不一定要是一个递进层级结构,也就是说网络中的某一层可以不仅仅依赖于紧邻的上一层的特征,而可以依赖于更前面层学习的特征;还有就是ResNet网络存在冗余。于是他们针对这两点设计了DenseNet, 让网络中的每一层都直接与其前面层相连,实现特征的重复利用;同时把网络的每一层设计得特别「窄」,即只学习非常少的特征图(最极端情况就是每一层只学习一个特征图),达到降低冗余性的目的.
这是整个DenseNet的网络结构,可以看到在每一个Block里面,各层之间是相互连接的,每一层的输入都包括了之前所有层的输出,这些输出通过concat连接在一起(ResNet是和),层内结构如下图所示:
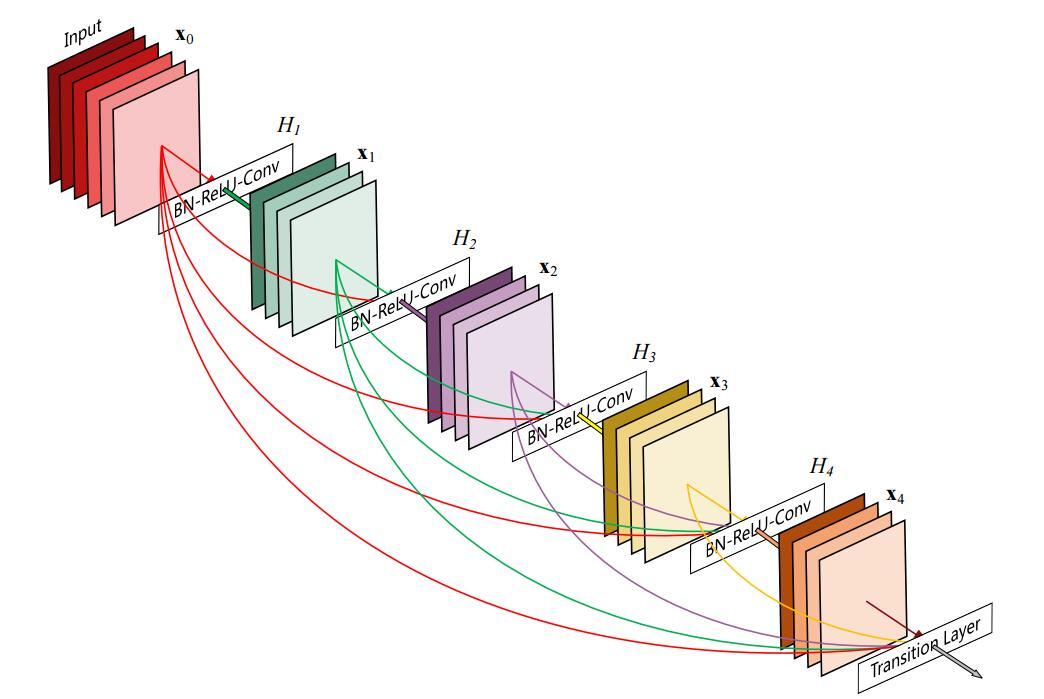
在每个Block之间,有一个过渡层,每个过渡层由BN层、1x1卷积层和2x2平均池化层组成,这个1x1的卷积主要是用来降维。这篇文章当中,作者提出了一个叫做增长速率的词,其实也就是输出的通道数。这里把每经过一层的输出通道数都进行固定,举个例子:假定增长率为k,如果某一个block的输入为w,那么在l层的输入就应该为w+k(l-1)。这里有一个解释:每一层都可以和它所在的block中之前的所有特征图进行连接,使得网络具有了*“集体知识”(collective knowledge)。可以将特征图看作是网络的全局状态。每一层相当于是对当前状态增加k(k为增长速率)个特征图。增长速率控制着每一层有多少信息对全局状态有效。全局状态一旦被写定,就可以在网络中的任何地方被调用,而不用像传统的网络结构那样层与层之间的不断重复。
作者在DenseBlock中还引入了一个1x1的卷积,也是用来降维,作者发现这种对densenet极为有效,因此作者将具有BN-ReLU-Conv(1x1)-BN-ReLU-Conv(3x3)的结构称为DenseNet-B。如果同时具有过渡层的11卷积降维,在block内部也有11的卷积降维,那么这个就称为DenseNet-BC
ResNeXt
结合了后面的Inception的想法,但却更有意思,很酷
总结下:split-transform-merge模式是作者归纳的一个很通用的抽象程度很高的标准范式,然后ResNeXt就这这一范式的一个简单标准实现,简洁高效啊。
(来自深度学习——分类之ResNeXt)
1x1卷积
推荐阅读:
原理:
这个工作的出发点是因为传统的卷积网络是在一个固定的patch上面线性加权,所以作者认为它对于特征的提取能力不够强,因此作者在卷积之后接了MLP,然后再输出。
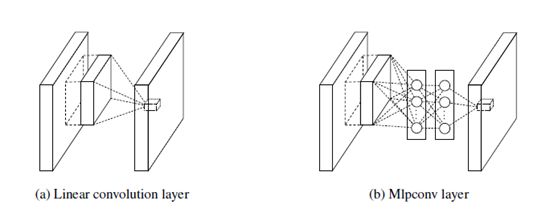 两者的差别
两者的差别
传统的卷积,就是直接加权求和,然后在relu就得到了一个值。传统的CNN求输出只是把卷积核对所有输入通道对应位置上的数字相加了,也就是说它是一个简单的线性求和,这是不是和我们的CNN所想要的不一样呢?于是goodFlow在13年做了一个工作,它引入了一个Maxout层,我个人的理解是类似于用来跨通道进行池化的,就是把几个通道对应位置上最大输出作为这几个通道的一个输出,而不再是简单的线性求和。这项工作的数学依据在于:任意的凸函数都可以由分段线性函数以任意精度拟合,所以最大池化层是一个能够拟合任意凸函数。
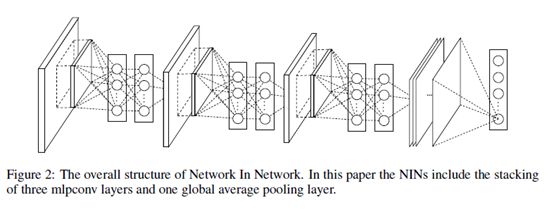
NIN的作者就想,你只能拟合任意凸函数,那还是不行,我要搞一个能够拟合任意函数的层出来。径向基神经网络和MLP可以逼近任意函数,但是MLP与BP算法更相容,并且能够加深网络,更加符合设计特征重利用的思路,所以选择MLP,这不就不Maxout更加牛逼了吗?于是NIN的流程就很容易理解了:先卷积,卷积之后进行relu,之后再对这个结果连接一个MLP卷积层,以MLP卷积层的输出经过relu之后作为下一层的输入。这里的MLP卷积层的实现是通过两次1x1的卷积来实现的,224x224的图像经过一个卷积核为1x1,步长为4的卷积之后大小变为了55x55,一共96个通道。用1x1x96去卷积一下获得了55x55x96,relu激活一下,再用同样大小的去卷积,也是获得55x55x96的特征输出,在经过relu一下便是下一层的输入。1*1的卷积核设计是一个非常巧妙的设计思路,对后来的GoogleNet, MoblieNet这些网络结构都产生了影响。这篇文章里面还有一个创新点就是采用了平均池化作为最后一层的输出,提升了它的泛化性能,这里就不仔细去介绍了。最终NIN在减小了大量的参数前提下,比AlexNet的精度并没有下降太多。
主要作用:
升维或降维
在不改变当前长度和宽度的情况下,改变通道的数量
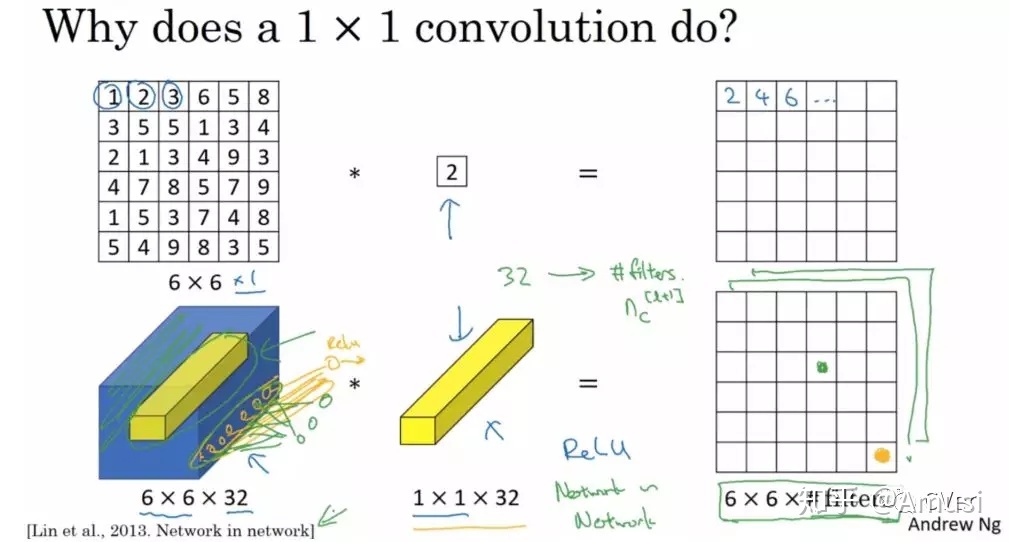
增加非线性
可以在保持feature map尺度不变的(即不损失分辨率)的前提下大幅增加非线性特性(利用后接的非线性激活函数),把网络做的很deep
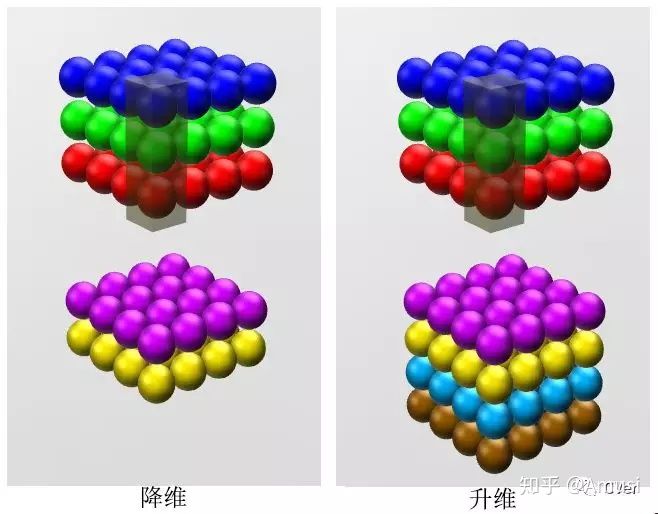
跨通道信息交互(channal 的变换)
例子:使用1x1卷积核,实现降维和升维的操作其实就是channel间信息的线性组合变化,3x3,64channels的卷积核后面添加一个1x1,28channels的卷积核,就变成了3x3,28channels的卷积核,原来的64个channels就可以理解为跨通道线性组合变成了28channels,这就是通道间的信息交互[7]。
注意:只是在channel维度上做线性组合,W和H上是共享权值的sliding window
减少计算量,
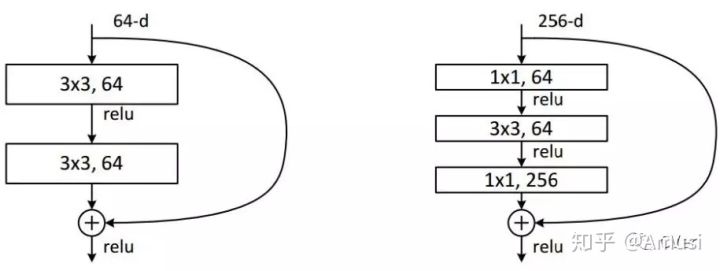
ResNet同样也利用了1×1卷积,并且是在3×3卷积层的前后都使用了,不仅进行了降维,还进行了升维,参数数量进一步减少,如下图的结构[8]。
其中右图又称为”bottleneck design”,目的一目了然,就是为了降低参数的数目,第一个1x1的卷积把256维channel降到64维,然后在最后通过1x1卷积恢复,整体上用的参数数目:1x1x256x64 + 3x3x64x64 + 1x1x64x256 = 69632,而不使用bottleneck的话就是两个3x3x256的卷积,参数数目: 3x3x256x256x2 = 1179648,差了16.94倍。
对于常规ResNet,可以用于34层或者更少的网络中,对于Bottleneck Design的ResNet通常用于更深的如101这样的网络中,目的是减少计算和参数量(实用目的)[9]。
还可以看【CNN】卷积神经网络中的 1*1 卷积 的作用里的例子
Inception
推荐阅读:
从Inception v1到Inception-ResNet,一文概览Inception家族的「奋斗史」
一文读懂物体分类AI算法:LeNet-5 AlexNet VGG Inception ResNet MobileNet
GoogLeNet 最大的特点就是使用了 Inception 模块,它的目的是设计一种具有优良局部拓扑结构的网络,即对输入图像并行地执行多个卷积运算或池化操作,并将所有输出结果拼接为一个非常深的特征图。因为 1x1、3x3 或 5x5 等不同的卷积运算与池化操作可以获得输入图像的不同信息,并行处理这些运算并结合所有结果将获得更好的图像表征。
另一方面,Inception 网络是复杂的(需要大量工程工作)。它使用大量 trick 来提升性能,包括速度和准确率两方面。它的不断进化带来了多种 Inception 网络版本的出现。
Inception v1
这是 Inception 网络的第一个版本。我们来分析一下它可以解决什么问题,以及如何解决。
在《Going deeper with convolutions》论文中,作者提出一种深度卷积神经网络 Inception,它在 ILSVRC14 中达到了当时最好的分类和检测性能。该架构的主要特点是更好地利用网络内部的计算资源,这通过一个精心制作的设计来实现,该设计允许增加网络的深度和宽度,同时保持计算预算不变。为了优化质量,架构决策基于赫布原则和多尺度处理。作者向 ILSVRC14 提交使用该架构的模型即 GoogLeNet,这是一个 22 层的深度网络,它的质量是在分类和检测领域进行了评估。
- 论文:Going deeper with convolutions
- 论文链接:https://arxiv.org/pdf/1409.4842v1.pdf
问题:
- 图像中突出部分的大小差别很大。例如,狗的图像可以是以下任意情况。每张图像中狗所占区域都是不同的。

从左到右:狗占据图像的区域依次减小(图源:https://unsplash.com/)
- 由于信息位置的巨大差异,为卷积操作选择合适的卷积核大小就比较困难。信息分布更全局性的图像偏好较大的卷积核,信息分布比较局部的图像偏好较小的卷积核。
- 非常深的网络更容易过拟合。将梯度更新传输到整个网络是很困难的。
- 简单地堆叠较大的卷积层非常消耗计算资源。
解决方案:
为什么不在同一层级上运行具备多个尺寸的滤波器呢?网络本质上会变得稍微「宽一些」,而不是「更深」。作者因此设计了 Inception 模块。
下图是「原始」Inception 模块。它使用 3 个不同大小的滤波器(1x1、3x3、5x5)对输入执行卷积操作,此外它还会执行最大池化。所有子层的输出最后会被级联起来,并传送至下一个 Inception 模块。
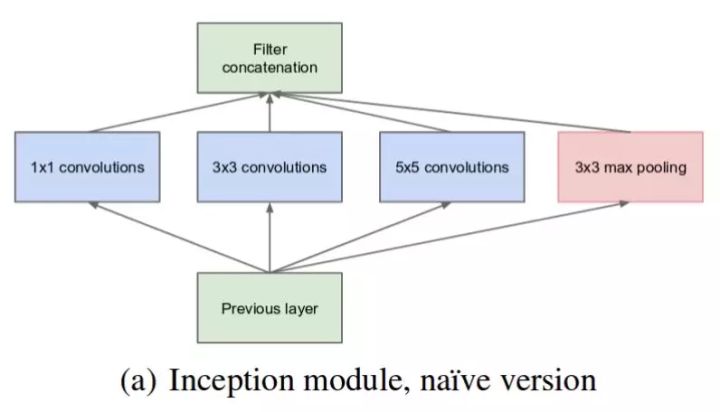
原始 Inception 模块。(图源:https://arxiv.org/pdf/1409.4842v1.pdf)
如前所述,深度神经网络需要耗费大量计算资源。为了降低算力成本,作者在 3x3 和 5x5 卷积层之前添加额外的 1x1 卷积层,来限制输入信道的数量。尽管添加额外的卷积操作似乎是反直觉的,但是 1x1 卷积比 5x5 卷积要廉价很多,而且输入信道数量减少也有利于降低算力成本。不过一定要注意,1x1 卷积是在最大池化层之后,而不是之前。
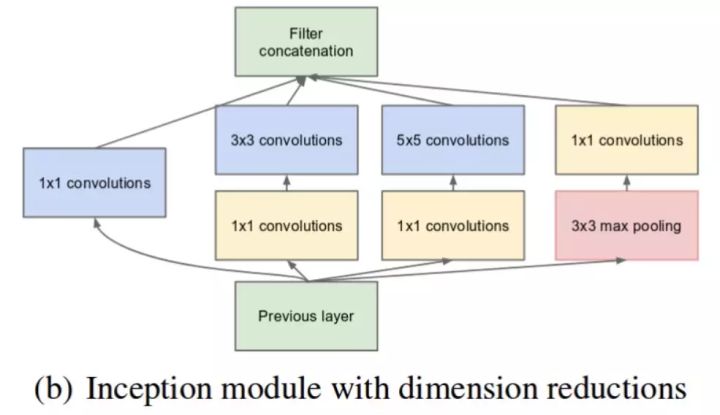
实现降维的 Inception 模块。(图源:https://arxiv.org/pdf/1409.4842v1.pdf)
利用实现降维的 Inception 模块可以构建 GoogLeNet(Inception v1),其架构如下图所示:
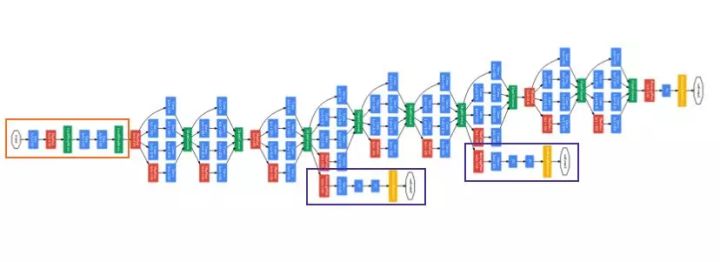
GoogLeNet。橙色框是 stem,包含一些初始卷积。紫色框是辅助分类器。较宽的部分是 inception 模块。(图源:https://arxiv.org/pdf/1409.4842v1.pdf)
GoogLeNet 有 9 个线性堆叠的 Inception 模块。它有 22 层(包括池化层的话是 27 层)。该模型在最后一个 inception 模块处使用全局平均池化。
不用多说,这是一个深层分类器。和所有深层网络一样,它也会遇到梯度消失问题。
为了阻止该网络中间部分梯度的「消失」过程,作者引入了两个辅助分类器(上图紫色框)。它们对其中两个 Inception 模块的输出执行 softmax 操作,然后在同样的标签上计算辅助损失。总损失即辅助损失和真实损失的加权和。该论文中对每个辅助损失使用的权重值是 0.3。
inceptionV2
inceptionV2和V1网络结构大体相似,其模型大小为40M左右,错误率仅4.8%,低于人眼识别的错误率5.1%。主要改进如下
- 使用两个串联3x3卷积来代替5x5卷积,从而降低参数量,并增加relu非线性。这一点参考了VGG的设计
- 提出了Batch Normalization。在卷积池化后,增加了这一层正则化,将输出数据归一化到0~1之间,从而降低神经元分布的不一致性。这样训练时就可以使用相对较大的学习率,从而加快收敛速度。在达到之前的准确率之后还能继续训练,从而提高准确率。V2达到V1的准确率时,迭代次数仅为V1的1/14, 从而使训练时间大大减少。最终错误率仅4.8%
inceptionV3
inceptionV3的网络结构也没太大变化,其模型大小96M左右。主要改进如下
- 使用非对称卷积。用1x3+3x1的卷积来代替一个3x3的卷积,降低了参数的同时,提高了卷积的多样性
- 分支中出现了分支。如下图
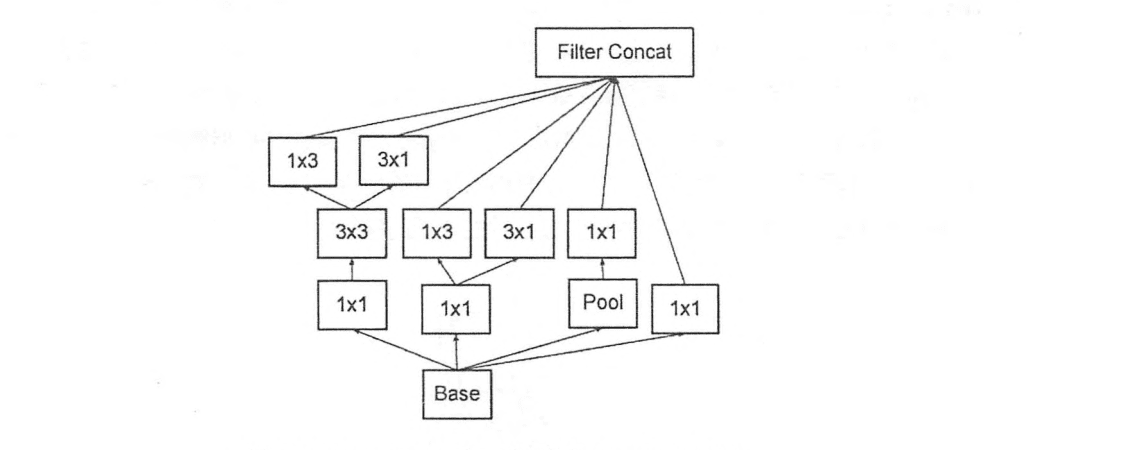
inceptionV4
inceptionV4主要是借鉴了resNet残差网络的思想,可以看做是inceptionV3和resNet的结合。inceptionV4模型大小163M,错误率仅仅为3.08%。主要在ResNet网络中讲解
卷积的细节
CNN中卷积层的计算细节,包括输入输出的维度,卷积计算的过程,参数数量等