尝试使用Tensorflow,教程为基础项目MNIST手写数字识别
Softmax回归
是一个线性的多类分类模型,实际上是从Logistic回归模型转化而来,区别于Logistic是二类分类模型,而他是多类分类模型
Softmax 函数的主要功能是将各个类别的分数转化为合理的概率值,例如一个样本可能属于3个类别,第一个个类别的打分为’a’,第二个类别的打分为‘b’,第三个类别的打分为‘c’。打分越高代表属于这个类别的概率越高,但是打分本身不代表概率,因为打分的值可以是负数,也可以很大,但概率要求僵必须在0~1,并且三类的概率加起来应该等于l。那么,如何将(a,b,c)转换成合理的概率值呢?方法就是使用Softmax函数:
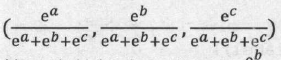
使得每个的分数都为正数且三个数值都在0~1之间,数值之和为1
假设x 是单个样本的特征, W、b 是Softmax模型的参数。在MNIST数据集中, x就代表输入图片,它是一个784维的向量,而W是一个矩阵,而W的形状为(784, 10),b是一个10维的向量, 10代表的是类别数。Softmax模型的第一步是通过下面的公式计算各个类别的Logit:
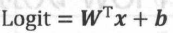
而Logit是一个10维的向量,而可以使用Softmax函数将它转换成各个类别的概率值
Softmax回归在Tensorflow中的实现—MNIST实验
1 | import scipy.misc |
实验结果
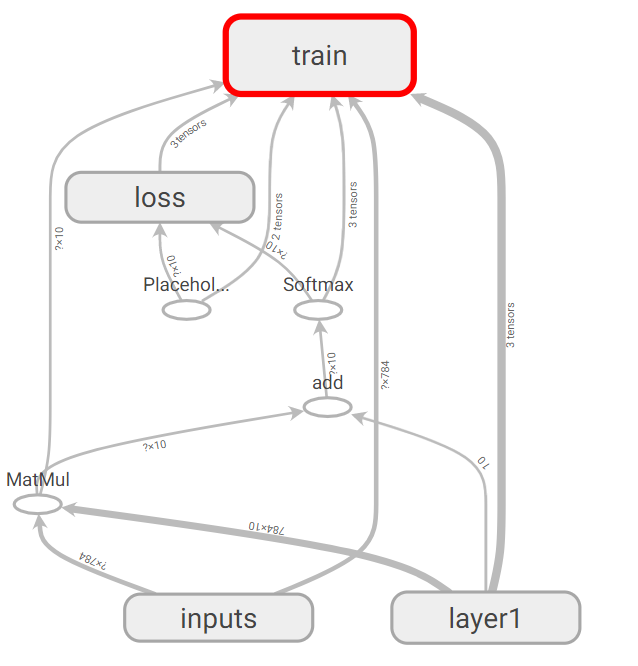
通过Tensorboard能够直观地看到训练的过程与训练的结构
1.Graph
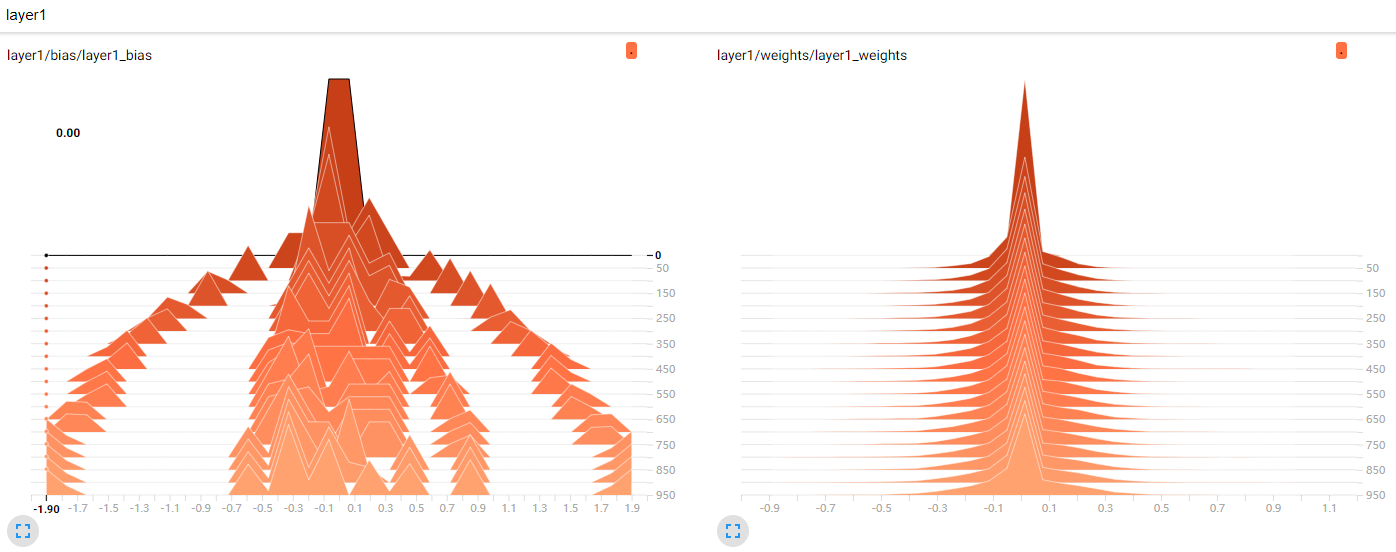
2.Histogram 中间层Weights和Bias
3.训练过程的损失函数变化:
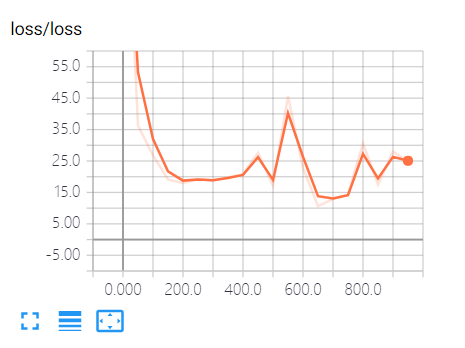
4.准确率
1 | #正确的预测结果 |