如何检验数据的正态性——-Check the normality of data
处理数据时,有时候需要观察数据分布,比如检验数据的正态性
图示法
直方图
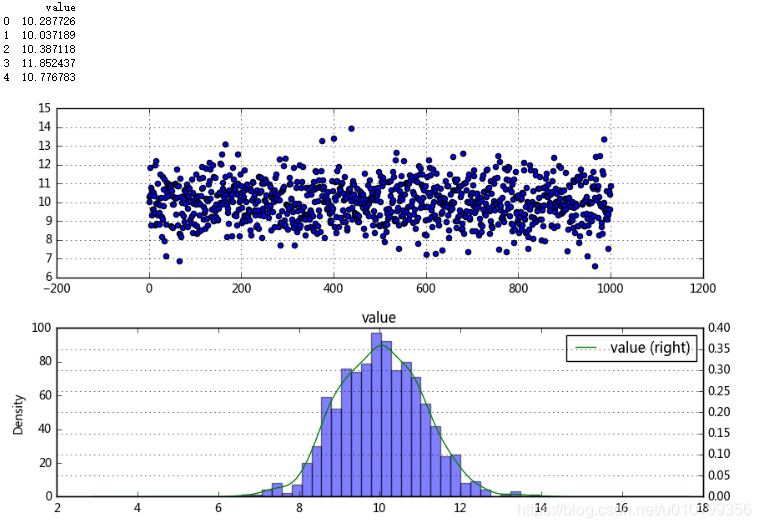
绘制数据直方图,直接观察趋势
1 | s = pd.DataFrame(np.random.randn(1000)+10,columns = ['value']) |
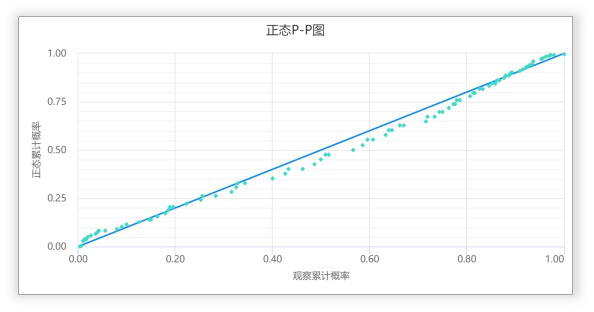
P-P图法
proportion-proportion plots
以样本的累计频率(百分比)作为横坐标,以按照正态分布计算的相应累计频率为纵坐标,把样本值表现为直角坐标系中的散点,把样本值表现为直角坐标系中的散点
如果资料服从正态分布,那样本点应该围绕着第一象限的对角线分布
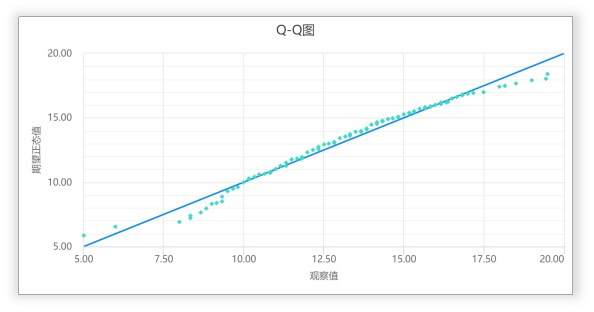
Q-Q图
quantile-quantile plots
以样本的分位数(Px)作为横坐标,以按照正态分布计算的相应分位数作为纵坐标,把样本值表现为直角坐标系中的散点
如果资料服从正态分布,那样本点应该围绕着第一象限的对角线分布
统计检验法
简单用法:
后面讲述具体,先来看看简单示例:
1 | import numpy as np |
W检验 / Shapiro 检验 / Shapiro-Wilk检验
专门用于检验正态分布,
官方手册:scipy.stat.shapiro https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.shapiro.html
原假设:样本数据符合正态分布
注意:shapiro是用来检验小样本数据 (For N > 5000 the W test statistic is accurate but the p-value may not be.)
scipy.stats.shapiro(x, a=None, reta=False)
一般我们只用 x 参数就行,x 即待检验的数据
K-S检验
方法:scipy.stats.kstest (rvs, cdf, args = ( ), N = 20, alternative =’two-sided’, mode =’auto’)
官方文档:scipy.stats.kstest https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.kstest.html
原理:KS-检验(Kolmogorov-Smirnov test) – 检验数据是否符合某种分布
kstest 是一个很强大的检验模块,除了正态性检验,还能检验 scipy.stats 中的其他数据分布类型,仅适用于连续分布的检验,
原假设:数据符合正态分布
对于正态性检验,我们只需要手动设置三个参数即可:
rvs:待检验的一组一维数据
cdf:检验方法,例如’norm’,’expon’,’rayleigh’,’gamma’,这里我们设置为’norm’,即正态性检验
alternative:默认为双尾检验,可以设置为’less’或’greater’作单尾检验
model: auto(默认),选取其中一个
‘approx’,使用检验统计量的精确分布的近视值,
‘asymp’:使用检验统计量的渐进分布
检验指定的数列是否服从正态分布
借助假设检验的思想,利用K-S检验可以对数列的性质进行检验,看代码:
1 | from scipy.stats import kstest |
首先生成1000个服从N(0,1)标准正态分布的随机数,在使用k-s检验该数据是否服从正态分布,提出假设:x从正态分布。
最终返回的结果,p-value=0.76584491300591395,比指定的显著水平(假设为5%)大,则我们不能拒绝假设:x服从正态分布。
这并不是说x服从正态分布一定是正确的,而是说没有充分的证据证明x不服从正态分布。因此我们的假设被接受,认为x服从正态分布。
如果p-value小于我们指定的显著性水平,则我们可以肯定的拒绝提出的假设,认为x肯定不服从正态分布,这个拒绝是绝对正确的。
检验指定的两个数列是否服从相同分布
1 | from scipy.stats import ks_2samp |
我们先分别使用beta分布和normal分布产生两个样本大小为1000的数列,使用ks_2samp检验两个数列是否来自同一个样本,提出假设:beta和norm服从相同的分布。
最终返回的结果,p-value=4.7405805465370525e-159,比指定的显著水平(假设为5%)小,则我们完全可以拒绝假设:beta和norm不服从同一分布。
Anderson-Darling test
方法:scipy.stats.anderson (x, dist =’norm’ )
该方法是由 scipy.stats.kstest 改进而来的,可以做正态分布、指数分布、Logistic 分布、Gumbel 分布等多种分布检验。默认参数为 norm,即正态性检验。
官方文档:SciPy v1.1.0 Reference Guide
参数:x - 待检验数据;dist - 设置需要检验的分布类型
返回:statistic - 统计数;critical_values - 评判值;significance_level - 显著性水平
1 | #生成标准正态随机数 |
矩法 / S-K检验
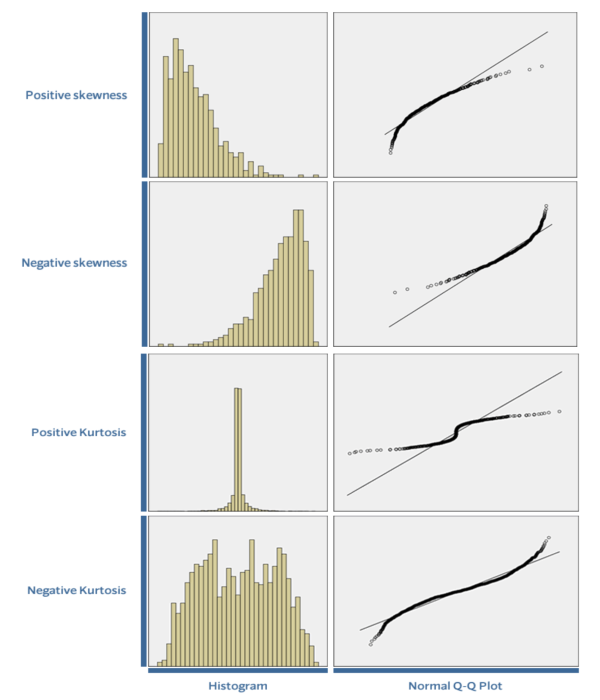
Skewness 偏度,kurtosis峰度
对分布的峰度与偏度进行检验
官方手册:scipy.stats.normaltest https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.normaltest.html
normaltest 也是专门做正态性检验的模块,原理是基于数据的skewness和kurtosis
scipy.stats.normaltest(a, axis=0, nan_policy=’propagate’)
a:待检验的数据
axis:默认为0,表示在0轴上检验,即对数据的每一行做正态性检验,我们可以设置为 axis=None 来对整个数据做检验
nan_policy:当输入的数据中有空值时的处理办法。默认为 ‘propagate’,返回空值;设置为 ‘raise’ 时,抛出错误;设置为 ‘omit’ 时,在计算中忽略空值。