目标检测方法:R-CNN/Fast R-CNN/Faster R-CNN/YOLO/SSD
状态有点不好,就先不自己总结了,记录下有价值的链接,留待之后再说
从R-CNN到RFBNet,深度目标检测5年纵览,文章+代码让你从入门到精通
CNN:包括CNN ResNet一直到Object Detection AndrewNG Deep learning课程笔记 - CNN
一些思考
为什么R-CNN需要SVM?
参考链接:为什么RCNN用SVM做分类而不直接用CNN全连接之后softmax输出?
一开始很不明白CNN和SVM的作用,后来明白,其实CNN只是用来提取特征的,真正做分类的是SVM
那么为什么需要有需要SVM在CNN之后做分类呢?
一方面,CNN训练需要大量的数据,所以在训练的时候,训练数据的IOU>0.5就认为是正类,其他都是负类,包括瞎选的背景,所以训练数据较多;而SVM训练的时候,GT才是正类,而负类是IoU<0.3,而中间的忽略
第二,也因为训练样本的选择方式不同,其实作者也用过softmax在cnn最后,但是效果不好,他分析,CNN训练,负样本是随机选取的,而不是SVM中用于训练的hard negative,所以分类mAP下降(具体可以看RCNN用SVM做分类而不用softmax)
那么,为什么SVM可以通过上述的选择方式提高性能呢?
参考上面链接中不可不疯癫的回答,说的很好,因为SVM不容易受到非支持向量样本的影响,而平常的LR容易受到所有样本的影响,能够适应于这种难例挖掘的时间
关于难负例挖掘问题,可以看薰风AI知识点:Hard Negative Mining/OHEM 你真的知道二者的区别吗?
候选框是怎么选择和训练的
通过对已有的框进行移动和放缩,看与真实坐标的差值
详见:边框回归(Bounding Box Regression)详解
Fast R-CNN
原来的R-CNN,先对完整图像提取ROI,对每一个ROI进行卷积,有大量的重复操作,Fast R-CNN是先对完整图像进行卷积提取特征,再提取ROI的对应特征,并且为了保证ROI不同区域的特征数在进入FCN前能统一,借鉴了SPP-net的池化方式,SPP-Net是把完整图像切割成16+4+1=21个,Fast R-CNN简化了一下,强制切成7*7
Faster R-CNN
虽然Fast-R-CNN效果不错,但是有个问题是他仍是需要先通过selective search找到proposal region,非常低效,而Faster R-CNN通过RPN(region proposal network)完成了侯选框的锚定,每一个像素取9个
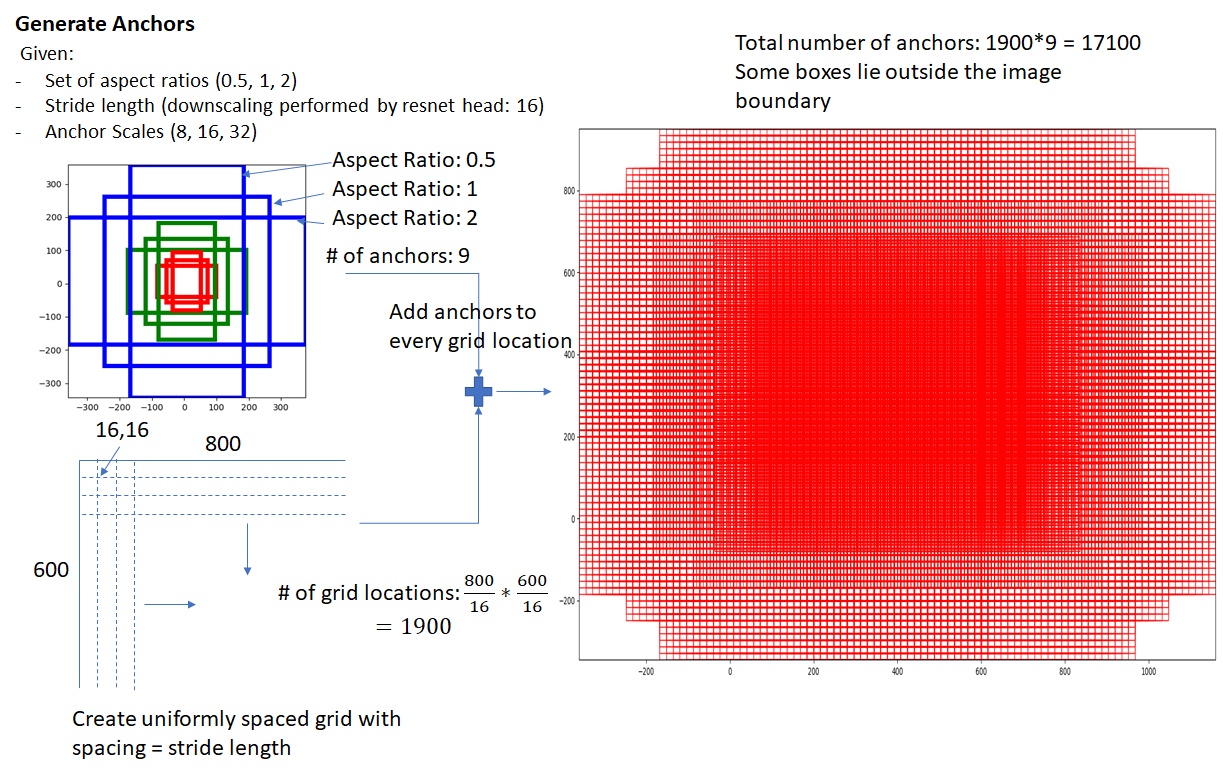
最全的介绍,非常好一文读懂Faster RCNN ,还有代码的解释捋一捋pytorch官方FasterRCNN代码
先分类还是想NMS
按道理应该可以先分类在NMS,但是一般情况下很少两个不同类别的叠加在附近,所有检测NMS后在分类
Yolo的图
图无敌了,快速理解YOLO目标检测