第二章的学习
2.2评估方法
2.2.1 留出法
“留出法” (hold-out)直接将数据集D划分为两个互斥的集合,其中一个集合作为训练集S,另一个作为测试集T, 即D=SUT,S∩T=ø,在S上训练出模型后,用T来评估其测试误差,作为对泛化误差的估计
2.2.2 交叉验证法
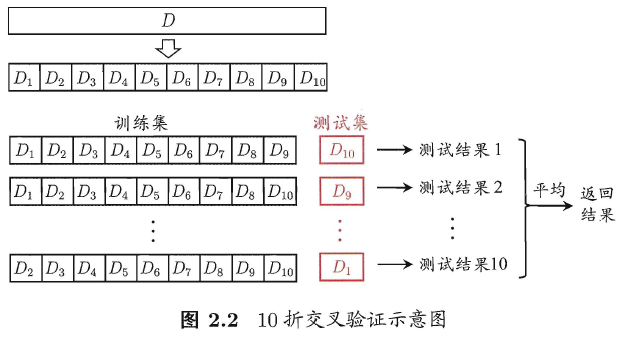
“交叉验证法” (cross validation)先将数据集D划分为k个大小相似的互斥子集, 即D = D1 U D2 U… U Dk, Di n Dj = ø (í ≠ j ) 。每个子集Di 都尽可能保持数据分布的一致性,即从D中通过分层采样得到. 然后,每次用k-1个子集的并集作为训练集;余下的那个子集作为测试集;这样就可获得k组训练/测试集,从而可进行k次训练和测试,最终返回的是这k个测试结果的均值
2.2.3 自助法(Bootstrapping)
“自助法” (bootstrapping)是一个比较好的解决方案,它直接以自助采样法(bootstrap sampling) 为基础[Efron and ibshirani, 1993]. 给定包含m个样本的数据集D ,我们对它进行采样产生数据集D’: 每次随机从D中挑选一个样本,将其拷贝放入D‘中,然后再将该样本放回初始数据集D中,使得该样本在下次采样时仍有可能被采到;这个过程重复执行m次后,我们就得到了包含m个样本的数据集D’,这就是自助采样的结果。显然,D中有一部分样本会在D’中多次出现,而另一部分样本不出现,可以做一个简单的估计,样本在m次采样中始终不被采到的概率是(1一1/m)^m , 取极限得到:
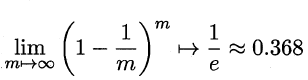
即通过自助来样,初始数据集D 中约有36.8%的样本未出现在采样数据集D’中.于是我们可将D’ 用作训练集,D\D’ 用作测试集;这样,实际评估的模型与期望评估的模型都使用m个训练样本,而我们仍有数据总量约1/3的、没在训练集中出现的样本用于测试。这样的测试结果,亦称”包外估计” (out-of-bagestimate).
2.2.4 调参与最终模型
参数设定范围和范围内的步长,得出需要评估的候选参数值,最终评估性能得出选定值
可以用验证集进行模型的评估和选择,从而调整超参数
2.3 性能度量(performance measure)
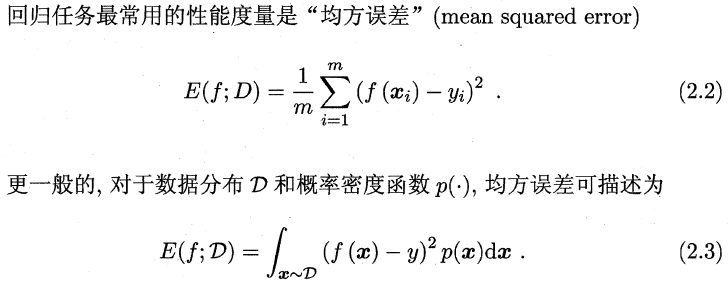
2.3.1 错误率和精度
错误率是分类错误的样本数占样本总数的比例,精度则是分类正确的样本数占样本总数的比例。对样例集D,分类错误率定义为

2.3.2 查准率(precision)、查全率(recall)与F1
对于二分类问题,可将样例根据其真实类别与学习器预测类别的组合划分为真正例(true positive) 、假正例(false positive) 、真反倒(true negative) 、假反例(false negative) 四种情形,令TP 、FP 、TN 、FN 分别表示其对应的样例数,则显然有TP+FP+TN+FN=样例总数.分类结果的”泪淆矩阵” (co时usion matrix) 如表2.1 所示

查准率和查全率是一对矛盾的度量.一般来说,查准率高时,查全率往往偏低;而查全率高时,查准率往往偏低
在很多情形札我们可根据学习器的预测结果对样例进行排序,排在前面的是学习器认为”最可能”是正例的样本?排在最后的则是学习器认为”最不可能”是正例的样本,按此顺序逐个把样本作为正例进行预测(如将每个样例的置信度作为区分正负的阈值,依次移动并划分),则每次可以计算出当前的查全率、查准率以查准率为纵轴、查全率为横轴作图,就得到了查准率-查全率曲线,简称” P-R 曲线”显示该曲线的图称为” P-R图” 图2 .3 给出了一个示意图
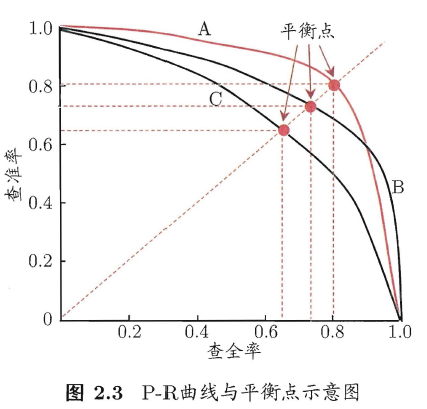
若如曲线B将曲线C完全包住,则可断言前者的性能优于后者,而如果发生了交叉,则需要具体比较,如比较PR曲线下面积的大小,在一定程度上表征了学习在查准率和查全率取得”双高“的比例,但这个值不太容易估算, 因此人们设计了一些综合考虑查准率、查全率的性能度量.
“平衡点” (Break-Event Point,简称BEP)就是这样一个度量,它是” 查准率=查全率”时的取值,但BEP还是过于简化了些,更常用的是F1度量:
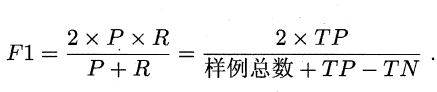
在一些应用中,对查准率和查全率的重视程度有所不同.例如在商品推荐系统中,为了尽可能少打扰用户,更希望推荐内容确是用户感兴趣的,此时查准率更重要;而在逃犯信息检索系统中,更希望尽可能少漏掉逃犯,此时查全率更重要. F1 度量的一般形式—Fß’ 能让我们表达出对查准率/查全率的不同偏好,它定义为
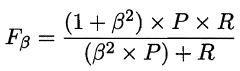

其中ß>0度量了查全率对查准率的相对重要性[Van Rijsbergen, 1979]. ß = 1时退化为标准的F1; ß> 1 时查全率有更大影响; ß < 1 时查准率有更大影响.
2.3.3 ROC(Receiver Operating Characteristic)与AUC(Area Under ROC Curve)
我们根据学习器的预测结果对样例进行排序,按此顺序逐个把样本作为正例进行预测,每次计算出两个重要量的值,分别以它们为横、纵坐标作图就得到了”ROC曲线“,与P-R曲线使用查准率、查全率为纵、横轴不同,ROC曲线的纵轴是”真正例率” (True Positive Rate,简称TPR) ,横轴是”假正例率” (False PositiveRate,简称FPR) ,基于表2.1 中的符号,两者分别定义为
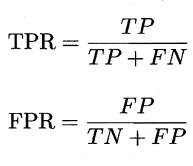

2.3.4 代价敏感错误率和代价曲线
非均等代价(Unequal cost)
代价曲线的绘制很简单: ROC 由线上每…点对应了代价平面上的二条线段7 设ROC 曲线上点的坐标为(TPR, FPR) ,则可相应计算出FNR,然后在代价平面上绘制一条从(O , FPR) 到(l , FNR) 的线段,线段下的面积即表示了该条件下的期望总体代价;如此将ROC 曲线土的每个点转化为代价平面上的一条线段,然后取所有线段的下界,围成的自积即为在所有条件下学习器的期望总体代价,