第一章的学习
基本术语
instance sample
attribute feature
attribute space / sample space
feature vector
dimensionality
ground-truth
Classification / Regression
Binary Classification: positive class 。 negative class
Clustering Cluster
Distribution
independent and identically distributed
induction :Generalization / inductive learning 样例中学习,归纳过程
deduction:Specialization 数学定理的推导
Inductive Bias 归纳偏好
Occam’s razor:“若有多个假设与观察一致,则选最简单的那一个”
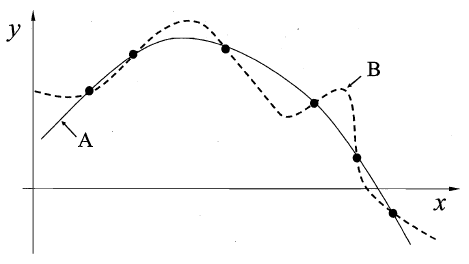
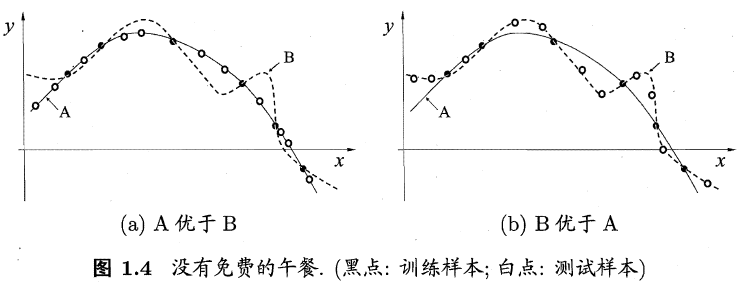
尽管我们了解到有时候过于复杂的划分模型常常是过拟合的,对于测试集的效果会很差,但是实际上,对于一个学习算法A而言,若他在某些问题上比算法B的性能优异,那么,则必然!对,必然存在另一些问题,使得算法B比A的性能要更好,这个结论对于任何的算法均是成立的。
为简单起见,假设样本空间X 和假设空间组都是离散的。令P( h I X,A)代表算法A基于训练数据X产生假设h的概率,再令f代表我们希望学习的真实目标函数。 A的”训练集外误差”,即A在训练、集之外的所有样本上的误差为:

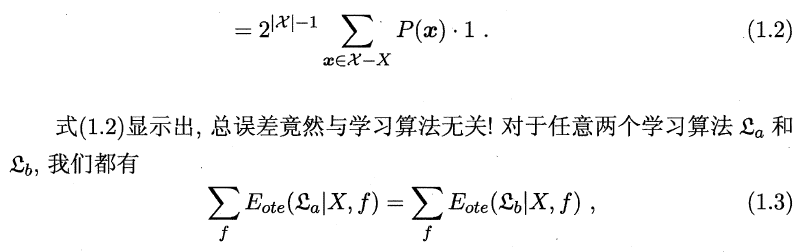
也就是说,无论学习算法A多聪明、学习算法B多笨拙,它们的期望性能竟相同!这就是”没有免费的午餐”定理(No Free Lunch Theorem,简称NFLWolpert, 1996; Wolpert and Macready, 1995]。
发展历程
二十世纪五十年代到七十年代初,人工智能研究处于”推理期”,那时人们以为只要能赋予机器逻辑推理能力,机器就能具有智能
从二十世纪七十年代中期开始,人工智能研究进入了”知识期”在这一时期,大量专家系统问世,在很多应用领域取得了大量成果,专家系统面临”知识工程瓶颈”,简单地说,就是由人来把知识总结出来再教给计算机是相当困难的。
五十年代中后期7 基于神经网络的”连接主义” (connectionism) 学习开始出现的代表性工作有F. Rosenblatt 的感知机(Perceptron) ;在六七十年代,基于逻辑表示的”符号主义” (symbolism)学习技术建勃发展
在二十世纪八十年代,”从样例中学习”的一大主流是符号主义学习,其代表包括决策树(decision tree)和基于逻辑的学习。典型的决策树学习以信息论为基础,以信息娟的最小化为目标,直接模拟了人类对概念进行判定的树形流程
二十世纪九十年代中期之前,“从样例中学习”的另一主流技术是基于神经网络的连接主义学习。与符号主义学习能产生明确的概念表示不同,连接主义学习产生的是”黑箱”模型,因此从知识获取的角度来看,连接主义学习技术有明显弱点;然而,由于有BP这样有效的算法,使得它可以在很多现实问题上发挥作用。事实上,BP一直是被应用得最广泛的机器学习算法之一。连接主义学习的最大局限是其”试错性’p; 简单地说?其学习过程涉及大量参数,而参数的设置缺乏理论指导,主要靠于工”调参”夸张一点说,参数调节上失之毫厘,学习结果可能谬以千里。
二十世纪九十年代中期”统计学习” (statistical learning) 闪亮登场并迅速占据主流舞台,代表性技术是支持向量机(Support Vector Machine,简称SVM) 以及更一般的”核方法” (kernel methods)。