太常见了,但是一直以为就是类似normalize,仔细查了下,感觉还是蛮有意思的,看了一些材料,做一个记录,感谢愿意分享的大佬们
Batch Normalization是神经网络训练中非常有用的神器,不仅能够减少对调参的依赖,加速训练,同时有很多改进如LN、WN等,很有意思,详情如下
Batch Normalization,BN,顾名思义,其实就是”批规范化”,batch好理解,就是mini-batch训练的那个batch,通过少量样本来训练,精华在于normalization,而这里的Normalization其实和数据预处理时的Normalization一个意思,不过结合上具体的训练过程就很有意思了
Why we need BN?
数据的独立同分布
independent and identically distributed,简称为 i.i.d. 是我们在做ML时最开心的了,这也是朴素贝叶斯为什么叫朴素贝叶斯的原因,因为i.i.d可以简化常规机器学习模型的训练、提升机器学习模型的预测能力,是一个共识。
所以,一般我们在把数据喂给model前,会先进行白化(whitening),主要目的是:
- 使得输入特征分布具有相同的均值与方差。其中PCA白化保证了所有特征分布均值为0,方差为1;而ZCA白化则保证了所有特征分布均值为0,方差相同;
- 去除特征之间的相关性。
(关于白化,可阅:机器学习(七)白化whitening)
但是白化:
- 白化过程计算成本太高,并且在每一轮训练中的每一层我们都需要做如此高成本计算的白化操作;
- 白化过程由于改变了网络每一层的分布,因而改变了网络层中本身数据的表达能力。底层网络学习到的参数信息会被白化操作丢失掉。
既然有了上面两个问题,那我们的解决思路就很简单,一方面,我们提出的normalization方法要能够简化计算过程;另一方面又需要经过规范化处理后让数据尽可能保留原始的表达能力。于是就有了简化+改进版的白化——Batch Normalization。
深度学习中的 Internal Covariate Shift
那么为什么深度学习会这么困难的,为啥咱们调参小心翼翼呢?
因为深度学习的层次通常比较多,而参数不断更新的时候,越高层的参数越容易因底层参数的调整而波动,不断去适应,所以我们需要非常谨慎地去设定参数,
Google 将这一现象总结为 Internal Covariate Shift,简称 ICS. 什么是 ICS 呢?@魏秀参 在一个回答中做出了一个很好的解释
大家都知道在统计机器学习中的一个经典假设是“源空间(source domain)和目标空间(target domain)的数据分布(distribution)是一致的”。如果不一致,那么就出现了新的机器学习问题,如 transfer learning / domain adaptation 等。而 covariate shift 就是分布不一致假设之下的一个分支问题,它是指源空间和目标空间的条件概率是一致的,但是其边缘概率不同,即:对所有
,
ICS导致的问题
简而言之,每个神经元的输入数据不再是“独立同分布”。
其一,上层参数需要不断适应新的输入数据分布,降低学习速度。
其二,下层输入的变化可能趋向于变大或者变小,导致上层落入饱和区,使得学习过早停止。
其三,每层的更新都会影响到其它层,因此每层的参数更新策略需要尽可能的谨慎。
General framework and basic ideas of BN
我的理解:先通过normalization,在通过计算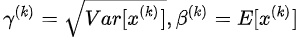 ,使得能够再还原回去,这是为了使得BN不剥夺底层辛苦训练出的数据分布信息,大佬们是叫做保证了模型的capacity
,使得能够再还原回去,这是为了使得BN不剥夺底层辛苦训练出的数据分布信息,大佬们是叫做保证了模型的capacity
主流 Normalization 方法梳理
查看详解深度学习中的Normalization,BN/LN/WN中的第三章
各种Normalization方法 为什么会有效?
查看详解深度学习中的Normalization,BN/LN/WN中的第四章
Why BN Work:
那BN到底是什么原理呢?说到底还是为了防止“梯度弥散”。关于梯度弥散,大家都知道一个简单的栗子:0.9^30≈0.04。在BN中,是通过将activation规范为均值和方差一致的手段使得原本会减小的activation的scale变大。可以说是一种更有效的local response normalization方法(见4.2.1节)。
Reference:
详解深度学习中的Normalization,BN/LN/WN
深度学习中 Batch Normalization为什么效果好?——魏秀参老师的回答