sklearn常用的各种
Preprocessing
1.Imputer缺失值处理
原本是属于preprocessing里的,from sklearn.preprocessing import Imputer,但是目前好像是独立了可以:from sklearn.impute import SimpleImputer or others,但是二者都可以使用
前者可以看 https://blog.csdn.net/kancy110/article/details/75041923
后者可以看 https://scikit-learn.org/stable/modules/impute.html#impute
和
https://scikit-learn.org/stable/modules/generated/sklearn.impute.SimpleImputer.html#sklearn.impute.SimpleImputer
2.LabelEncoder和OneHotEncoder
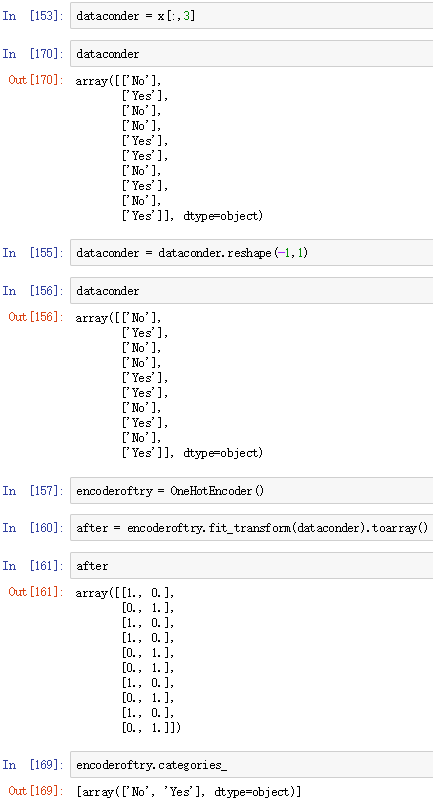
LabelEncoder类别编码将属性转化为数值
OneHotEncoder独热编码把特征转化为独热编码,方便进行训练
(为什么需要独热编码:为了更好地衡量离散化特征的区别 https://www.imooc.com/article/35900)
Label和OneHot的使用说明:
https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.OneHotEncoder.html#sklearn.preprocessing.OneHotEncoder
把标签转换为OneHot编码:
3、数值预处理:二值化、标准化、归一化
Binarizer二值化:
sklearn.preprocessing.`Binarizer(threshold=0.0, copy=True)
官方文档:
https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.Binarizer.html#sklearn.preprocessing.Binarizer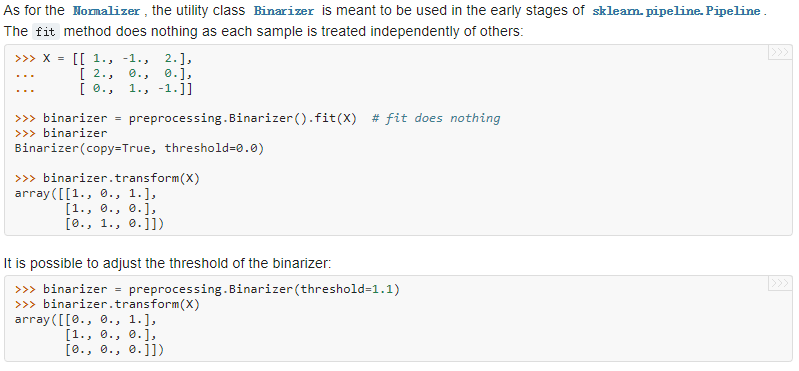
StandardScaler标准化:
sklearn.preprocessing.`StandardScaler(copy=True, with_mean=True, with_std=True)
转换公式:z = (x - u) / s

Normalizer正则化:
sklearn.preprocessing.Normalizer`(norm=’l2’, copy=True)
Compare the effect of different scalers on data with outliers
Model selection
1.数据集切分train_test_split
sklearn.model_selection.train_test_split`(arrays, options*)
Metrics
衡量训练的效果,包括各种损失函数和判准
官方文档:
https://scikit-learn.org/stable/modules/classes.html#module-sklearn.metrics