关于常用的numpy库的部分说明
asarray和array的区别
array和asarray都可以将结构数据转化为ndarray,但是主要区别就是当数据源是ndarray时,array仍然会copy出一个副本,占用新的内存,属于深拷贝。
但asarray不会
数据展为一维
ravel(),flatten(),squeeze()三个都有将多维数组转化为一维数组的功能:
ravel(): 不会产生原来数据的副本
flatten():返回源数据副本
squeeze():只能对维度为1的维度降维
reshape(-1):可以拉平多维数组
【一看就懂】ravel()、flatten()、squeeze(),reshape()的用法与区别
numpy version and the configuration
1 | np.__version__ |
random
https://blog.csdn.net/kancy110/article/details/69665164 Numpy之random学习
linspace
https://blog.csdn.net/you_are_my_dream/article/details/53493752 numpy.linspace使用详解
poly1d
https://www.cnblogs.com/zhouzhe-blog/p/9621679.html 深度学习之numpy.poly1d()函数]
np.linalg.norm
求范数 可在计算距离时使用
https://blog.csdn.net/hqh131360239/article/details/79061535
官方文档:https://docs.scipy.org/doc/numpy/reference/generated/numpy.linalg.norm.html
np.intersect1d
矩阵相同
find common values between two arrays? (★☆☆)
Z1 = np.random.randint(0,10,10)
Z2 = np.random.randint(0,10,10)
print(np.intersect1d(Z1,Z2))
np.unravel_index()
找出数值的下标
np.unravel_index(100,(6,7,8))
np.identify()
产生单位矩阵
np.eye()
也可以产生单位矩阵,但同时中间的斜线轴可以移动,
meshgrid和linspace
meshgrid生成网格坐标:把两个数组的笛卡尔积内的元素的第一二个坐标分别放入两个矩阵中
linspace生成等间距变量,可以合用产生坐标轴
1 | a = np.linspace(10,30,3) |
忽略numpy的警告?
How to ignore all numpy warnings (not recommended)? (★☆☆)
1 | # Suicide mode on |
获得日期
the dates of yesterday, today and tomorrow?
1 | yesterday = np.datetime64('today', 'D') - np.timedelta64(1, 'D') |
获得当月所有日期
How to get all the dates corresponding to the month of July 2016?
1 | Z = np.arange('2016-07', '2016-08', dtype='datetime64[D]') |
用五种方法抽取随机矩阵的整数部分(只想到一种)
Extract the integer part of a random array using 5 different methods (★★☆)
1 | Z = np.random.uniform(0,10,10) |
对一个小数组用比np.sum快的方法求和?
How to sum a small array faster than np.sum? (★★☆)
当参数是一个numpy数组时,np.sum最终调用add.reduce来完成工作。处理其参数和调度add.reduce的开销是np.sum较慢的原因。
1 | # Author: Evgeni Burovski |
比较两个随机数组是否相等
42.Consider two random array A and B, check if they are equal (★★☆)
1 | A = np.arange(0,2,5) |
创建一个不可变数组(只读)
Make an array immutable (read-only) (★★☆)
1 | Z = np.zeros(10) |
替换最大值
np.argmax和np.argmin
Z[Z.argmax()] = 0
创建一个xy的数组结构,包含[0,1]
46.Create a structured array with x and y coordinates covering the [0,1]x[0,1] area (★★☆)
坐标矩阵
1 | Z = np.zeros((5,5), [('x',float),('y',float)]) |
输出全部矩阵
How to print all the values of an array? (★★☆)’)
np.set_printoptions()——控制How to print all the values of an array? (★★☆)’)输出方式
1 | np.set_printoptions(threshold=np.nan) |
如何在向量中找到指定范围的最近值?
How to find the closest value (to a given scalar) in a vector?
1 | Z = np.arange(100) |
结构化数组
Create a structured array representing a position (x,y) and a color (r,g,b) (★★☆)
1 | z = np.zeros(10,[ ('pos', [('x',float,1), |
具体可以参考:Numpy 系列(九)- 结构化数组
转换矩阵类型 float(32)-integer32(32)
1 | z = np.arange(10,dtype=np.float32) |
StringIO读取内容至内存
关于StringIO可以查看:python 的StringIO
其中,关于genfromtxt:
Python 并没有提供数组功能,虽然列表 (list) 可以完成基本的数组功能,但它并不是真正的数组,而且在数据量较大时,使用列表的速度就会慢的让人难受。为此,Numpy 提供了真正的数组功能,以及对数据快速处理的函数。Numpy 还是很多更高级的扩展库的依赖库,例如: Scipy,Matplotlib,Pandas等。此外,值得一提的是:Numpy 内置函数处理数据的速度是 C 语言级别的,因此编写程序时,应尽量使用内置函数,避免出现效率瓶颈的现象。一切计算源于数据,那么我们就来看一看Numpy.genfromtxt 如何优雅的处理数据。
可以查看:Python科学计算——Numpy.genfromtxt
1 | from io import StringIO |
枚举enumerate
np.ndenumerate()或者np.ndindex
1 | Z = np.arange(9).reshape(3,3) |
提取和替换
np.take,提供下标,提取数据
1 | a = np.arange(10).reshape(2,5) |
np.put,提供下标,替换数据
1 | a = np.arange(10).reshape(2,5) |
根据某一列数据排序
np.argsort():argsort函数返回的是数组值从小到大的索引值
1 | Z = np.random.randint(0,10,(3,3)) |
any:
any() 函数用于判断给定的可迭代参数 iterable 是否全部为 False,则返回 False,如果有一个为 True,则返回 True。
元素除了是 0、空、FALSE 外都算 TRUE,函数等价于:
1 | def any(iterable): |
寻找最接近的数-迭代器flat
先减去待匹配的数,取绝对值,找到当前数组中最小的值,取其坐标,输出原数组中对应下标的值
可以通过flat来通过下标取值,同时flat是数组的迭代器,具体可看:numpy中flat/flatten用法区别
1 | Z = np.random.uniform(0,1,10) |
使用迭代器计算1x3和3x1的数组的和?
1 | A = np.arange(3).reshape(3,1) |
迭代器:
nditer —— numpy.ndarray 多维数组的迭代
创建一个有名字的数组类
通过类来创建含有名字的数组
其中,array和asarray都可以将结构数据转化为ndarray,但是主要区别就是当数据源是ndarray时,array仍然会copy出一个副本,占用新的内存,但asarray不会。
1 | class NamedArray(np.ndarray): |
对一个给定数组,如何按第二个数组表示的索引位置将对应的元素+1,注意重复的位置要重复加1?——指定位置加数
1 | Z = np.ones(10) |
…
好像是取全部的意思?我靠这东西查不到,真实见鬼
1 | a = np.arange(10).reshape(2,5) |
交换数组的两行
1 | sample72 = np.random.choice(100,16).reshape(4,-1) |
按下标按行按列求和
numpy.cumsum():
numpy.cumsum(a, axis=None, dtype=None, out=None)
axis=0,按照行累加。
axis=1,按照列累加。
axis不给定具体值,就把numpy数组当成一个一维数组。
计数bincount
numpy 统计数组的值出现次数与np.bincount()详细解释
从数组中找出最大的n个值
1 | Z = np.arange(50) |
从常规数组创建结构化数组?
1 | Z = np.array([("Hello", 2.5, 3), |
用三种方法计算一个大型数组中每个元素的立方
1 | Z = np.random.choice(100,10000) |
给定数组A,B,使用函数einsum实现求和,矩阵相乘,内积和外积
1 | #使用einsum函数,我们可以使用爱因斯坦求和约定(Einstein summation convention)在NumPy数组上指定操作 |
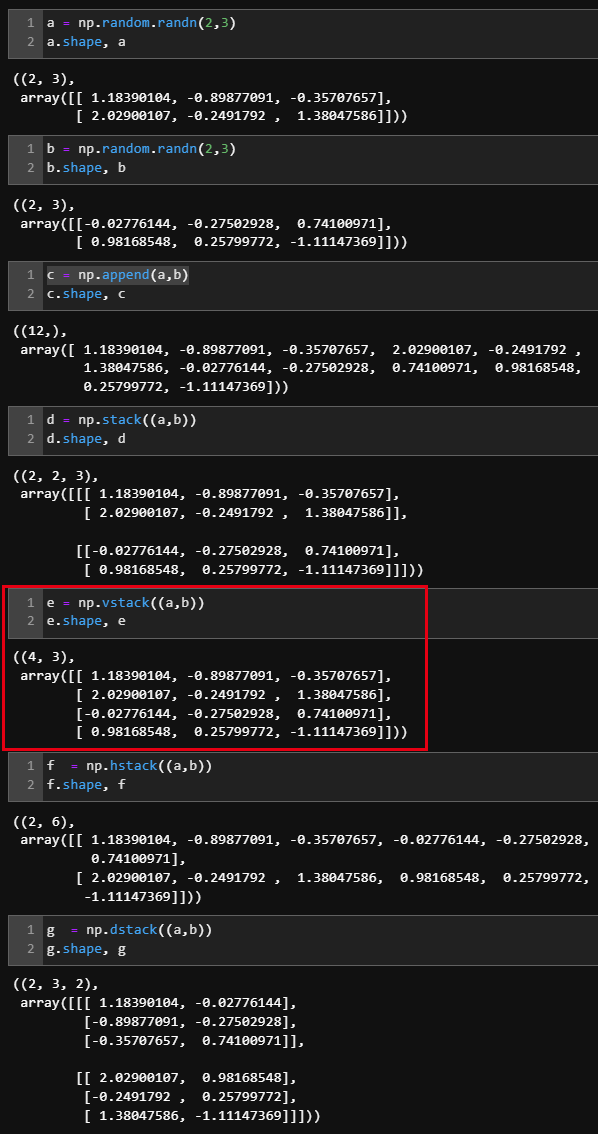
矩阵拼接
排序/sort/argsort/partrition/argpartrition
1.np.sort()
1 | np.sort(a, axis=-1, kind='quicksort', order=None) |
| 参数 | 参数说明 |
|---|---|
| a | 待排序数组array |
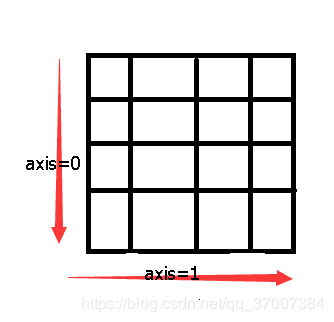
| axis=-1 | 默认按最后一个轴进行排序,axis=0,按行进行排序,axis=1,按列进行排序,简单示意图如下 |
| kind | 具体采用的排序方法,有{‘quicksort’, ‘mergesort’, ‘heapsort’}可供选择一般默认即可 |
| order | 一个字符串或列表,可以按照某个属性进行排序,当a是一个定义了字段的数组时有用 |
直接排序,返回排序后的数组
具体示例: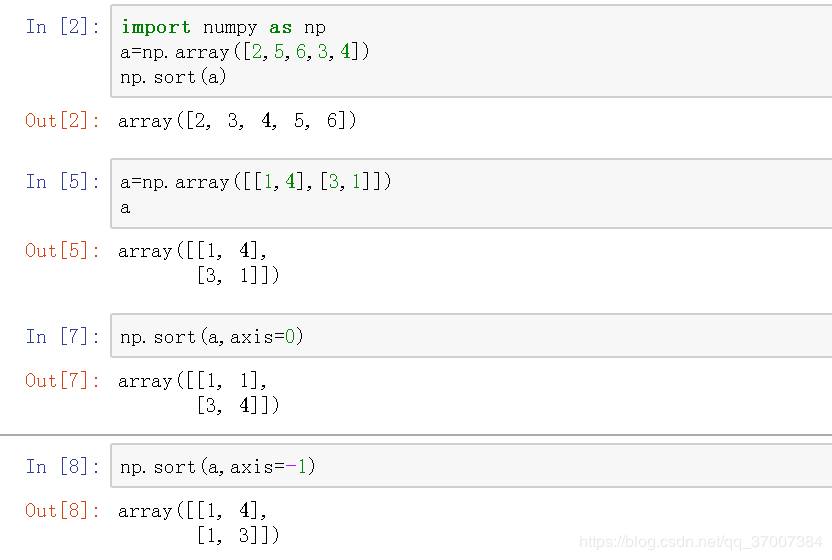
关于order参数,创建如下结构数组:
按照指定属性进行排序:

2.np.argsort()
与sort基本一致,不过不是返回的排序完成后的元素数组,而是排序完成后相应元素对应的索引数组
元素2对应索引0,元素3对应索引3等等
3.np.partition()
要了解argpartition()方法最好先了解partition(),因为argpartition()只不过是在partition()的基础上返回排序完成数组的索引号罢了
1 | partition(a, kth, axis=-1, kind='introselect', order=None) |
| 参数 | 参数说明 |
|---|---|
| a | 待排序数组array |
| kth | 数组元素中从小到大的第k个值将在处于其最终排序位置k(下面例子具体说明) |
| axis=-1 | 默认按最后一个轴进行排序 |
| kind | 具体采用的排序方法,一般默认即可 |
| order | 一个字符串或列表,可以按照某个属性进行排序,当a是一个定义了字段的数组时有用 |
具体例子

表示数组a中第2小的元素即元素2位于排序完成数组b的第二个位置上,即索引b[1]处,然后小于该元素的位于该元素左边,大于该元素的位于右边,左右两边没有特别的排序要求,只要求左边小于该元素,右边大于该元素即可

表示数组a中第4小的元素即元素6位于排序完成数组b的第四个位置上,即索引b[3]处

kth也可以是负数
表示数组a中第2大的元素即元素8位于排序完成数组b的倒数第2个位置上,即索引b[-2]处
当然,这有个什么用啊?用处之一就是如果我们有一个非常大的数组,假如我们想要找到其中最大的10个数,怎么办呢,我们可以用sort函数,然后排序完成后取出来,但是数组太大时这一方法比较耗时,所以我们可以采用partition函数,partition只对数组进行一遍排序,找到k位置的数即可,而对k位置左右的排序不关心,工作量少意味着其效率快
假如我们想找到a中的最大3个元素,我们该怎么操作呢?
相应找到最小的3个元素也很简单:
4.argpartition()
与partition()类似,不过返回的不是分区排序好的元素数组,而是排序完成的元素索引数组
如:
其中元素3对应索引4,元素4对应索引5,元素5对应索引1,等等