记得一开始学习Python的时候就有人说它比较慢,虽然至今我还没感受到慢(主要还是因为自己菜,写的程序不够。。
但是今天刷LeetCode的时候看到有人提到用numba进行加速,就还蛮好奇的,想起之前有收藏了几篇关于Python加速的文章,今天就稍微了解一下~当然,只是一些我目前了解到的知识,自娱自乐吧
目标很明确,加速,冲!
那么咋做呢?
那指定就是软硬兼施了,接下来就提两种方式:
CuPy
先整点硬的,CuPy库,Cu就是CUDA的意思,ok,明朗了,和TensorFlow、pytorch一样的,用GPU来加速:
介绍:
CuPy 是一个借助 CUDA GPU 库在英伟达 GPU 上实现 Numpy 数组的库。基于 Numpy 数组的实现,GPU 自身具有的多个 CUDA 核心可以促成更好的并行加速。
CuPy 接口是 Numpy 的一个镜像,并且在大多情况下,它可以直接替换 Numpy 使用。只要用兼容的 CuPy 代码替换 Numpy 代码,用户就可以实现 GPU 加速。
CuPy 支持 Numpy 的大多数数组运算,包括索引、广播、数组数学以及各种矩阵变换。
如果遇到一些不支持的特殊情况,用户也可以编写自定义 Python 代码,这些代码会利用到 CUDA 和 GPU 加速。整个过程只需要 C++格式的一小段代码,然后 CuPy 就可以自动进行 GPU 转换,这与使用 Cython 非常相似。
使用
在开始使用 CuPy 之前,用户可以通过 pip 安装 CuPy 库:
1 | pip install cupy |

CuPy 安装之后,用户可以像导入 Numpy 一样导入 CuPy:
1 | import numpy as np |
在接下来的编码中,Numpy 和 CuPy 之间的切换就像用 CuPy 的 cp 替换 Numpy 的 np 一样简单。如下代码为 Numpy 和 CuPy 创建了一个具有 10 亿参数 的 3D 数组。为了测量创建数组的速度,用户可以使用 Python 的原生 time 库:
1 | ### Numpy and CPU |
这很简单!
令人难以置信的是,即使以上只是创建了一个数组,CuPy 的速度依然快得多。Numpy 创建一个具有 10 亿 参数的数组用了 1.68 秒,而 CuPy 仅用了 0.16 秒,实现了 10.5 倍的加速。
但 CuPy 能做到的还不止于此。
比如在数组中做一些数学运算。这次将整个数组乘以 5,并再次检查 Numpy 和 CuPy 的速度。
1 | ### Numpy and CPU |
果不其然,CuPy 再次胜过 Numpy。Numpy 用了 0.507 秒,而 CuPy 仅用了 0.000710 秒,速度整整提升了 714.1 倍。
现在尝试使用更多数组并执行以下三种运算:
- 数组乘以 5
- 数组本身相乘
- 数组添加到其自身
1 | ### Numpy and CPU |
结果显示,Numpy 在 CPU 上执行整个运算过程用了 1.49 秒,而 CuPy 在 GPU 上仅用了 0.0922 秒,速度提升了 16.16 倍。
数组大小(数据点)达到 1000 万,运算速度大幅度提升
使用 CuPy 能够在 GPU 上实现 Numpy 和矩阵运算的多倍加速。值得注意的是,用户所能实现的加速高度依赖于自身正在处理的数组大小。下表显示了不同数组大小(数据点)的加速差异:
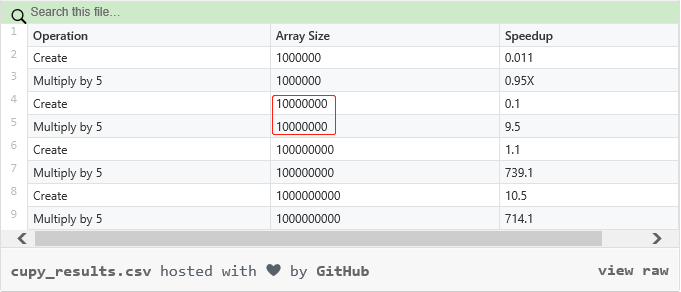
数据点一旦达到 1000 万,速度将会猛然提升;超过 1 亿,速度提升极为明显。Numpy 在数据点低于 1000 万时实际运行更快。此外,GPU 内存越大,处理的数据也就更多。所以用户应当注意,GPU 内存是否足以应对 CuPy 所需要处理的数据。
参考:
原文链接:**https://towardsdatascience.com/heres-how-to-use-cupy-to-make-numpy-700x-faster-4b920dda1f56
中文翻译 :这一招将 Numpy 加速 700 倍!!!
Numba
硬的整完,制定还有软的
其实我记得很早在接触Python的时候,听有人讲python慢的时候,还听说了python是C写的,其实还真的是,这涉及到解释器的问题,可以参考博客:Python解释器
介绍
Numba是python的即时(Just-In-Time,JIT)解释器,即当我们调用python函数时,我们的全部或者部分代码就会被转换成“即时”执行的机器码,将以我们的本地机器码速度运行,
它由 Anaconda 公司赞助,并得到了许多其他组织的支持。
在 Numba 的帮助下,您可以加速所有计算负载比较大的 python 函数(例如循环)。它还支持 numpy 库!所以,您也可以在您的计算中使用 numpy,并加快整体计算,因为 python 中的循环非常慢。 您还可以使用 python 标准库中的 math 库的许多函数,如 sqrt 等。有关所有兼容函数的完整列表,请查看此处。
为什么是他
为什么有了cpython和pypy了还要选择numba?
因为他贼方便,他只需要添加一个包装器(装饰器)到我们的函数上,就可以了,和原生python并无二致,如:
1 | from numba import jit |
我们可以不需要为了获得一些的加速来改变您的代码,这与您从类似的具有类型定义的 cython 代码获得的加速相当
使用:
以下测试代码的jupyter code:Speed Up Your Algorithms
Numba 使用 LLVM 编译器基础结构 将原生 python 代码转换成优化的机器码。使用 numba 运行代码的速度可与 C/C++ 或 Fortran 中的类似代码相媲美。
以下是代码的编译方式:
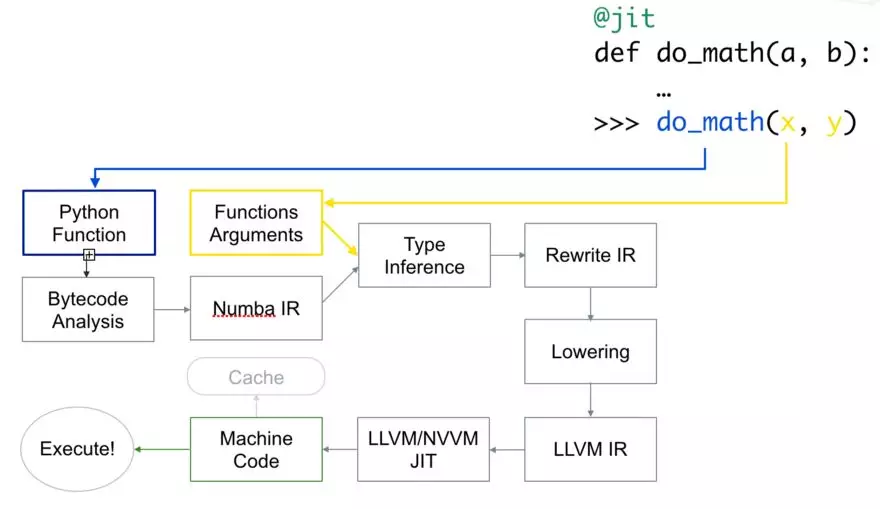
首先,Python 函数被传入,优化并转换为 numba 的中间表达,然后在类型推断(type inference)之后,就像 numpy 的类型推断(所以 python float 是一个 float64),它被转换为 LLVM 可解释代码。 然后将此代码提供给 LLVM 的即时编译器以生成机器码。
您可以根据需要在运行时或导入时 生成 机器码,导入需要在 CPU(默认)或 GPU 上进行。
使用 numba 的基本功能(只需要加上 @jit !)
为了获得最佳性能,建议在jit装饰器加上nopython=True参数,加上后就不会使用Python自带的解释器了,或者也可以使用@njit,如果加上 nopython=True的装饰器失败并报错,您可以用简单的 @jit 装饰器来编译您的部分代码,对于它能够编译的代码,将它们转换为函数,并编译成机器码。然后将其余部分代码提供给 python 解释器。
1 | from numba import njit, jit |
使用numba的时候,要先确认咱们确实有用到可以被numda解释和优化的,否者检查完,numba并不会编译任何东西,反而使得更慢了,因为存在numba内部代码检查的额外开销
还有更好的一点是,numba 会对首次作为机器码使用后的函数进行缓存。 因此,在第一次使用之后它将更快,因为它不需要再次编译这些代码,如果您使用的是和之前相同的参数类型。
如果代码是 可并行化 的,也可以传递 parallel=True 作为参数,但它必须与 nopython=True 一起使用,目前这只适用于CPU。
我们还可以指定函数具有的函数签名,这样会使得对任何其他类型的参数进行编译,如:
1 | from numba import jit, int32 |
就指定了该函数只能接收2个int32类型的参数并返回一个int32类型的值,通过该方式,我们可以更好的控制函数
如果需要,我们可以传递多个函数签名
您还可以使用 numba 提供的其他装饰器:
- @vectorize:允许将标量参数作为 numpy 的 ufuncs 使用,
- @guvectorize:生成 NumPy 广义上的
ufuncs, - @stencil:定义一个函数使其成为 stencil 类型操作的核函数
- @jitclass:用于 jit 类,
- @cfunc:声明一个函数用于本地回调(被C/C++等调用),
- @overload:注册您自己的函数实现,以便在
nopython模式下使用,例如:@overload(scipy.special.j0)。
Numba 还有 Ahead of time(AOT)编译,它生成不依赖于 Numba 的已编译扩展模块。 但:
- 它只允许常规函数(ufuncs 就不行),
- 您必须指定函数签名。并且您只能指定一种签名,如果需要指定多个签名,需要使用不同的名字。
它还根据您的CPU架构系列生成通用代码。
@vectorize 装饰器
通过使用 @vectorize 装饰器,您可以对仅能对标量操作的函数进行转换,例如,如果您使用的是仅适用于标量的 python 的 math 库,则转换后就可以用于数组。 这提供了类似于 numpy 数组运算(ufuncs)的速度。 例如:
1 |
|
您还可以将 target 参数传递给此装饰器,该装饰器使 target 参数为 parallel 时用于并行化代码,为 cuda 时用于在 cuda\GPU 上运行代码。
1 |
|
使 target=“parallel” 或 “cuda” 进行矢量化通常比 numpy 实现的代码运行得更快,只要您的代码具有足够的计算密度或者数组足够大。如果不是,那么由于创建线程以及将元素分配到不同线程需要额外的开销,因此可能耗时更长。所以运算量应该足够大,才能获得明显的加速。
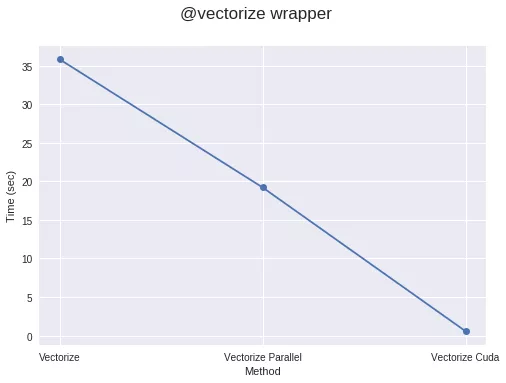
在GPU上运行函数
您也可以像装饰器一样传递 @jit 来运行 cuda/GPU 上的函数。 为此您必须从 numba 库中导入 cuda。 但是要在 GPU 上运行代码并不像之前那么容易。为了在 GPU 上的数百甚至数千个线程上运行函数,需要先做一些初始计算。 实际上,您必须声明并管理网格,块和线程的层次结构。这并不那么难。
要在GPU上执行函数,您必须定义一个叫做 核函数 或 设备函数 的函数。首先让我们来看 核函数。
关于核函数要记住一些要点:
a)核函数在被调用时要显式声明其线程层次结构,即块的数量和每块的线程数量。您可以编译一次核函数,然后用不同的块和网格大小多次调用它。
b)核函数没有返回值。因此,要么必须对原始数组进行更改,要么传递另一个数组来存储结果。为了计算标量,您必须传递单元素数组。
1 | # Defining a kernel function |
因此,要启动核函数,您必须传入两个参数:
- 每块的线程数,
- 块的数量。
例如:
1 | threadsperblock = 32 |
每个线程中的核函数必须知道它在哪个线程中,以便了解它负责数组的哪些元素。Numba 只需调用一次即可轻松获得这些元素的位置。
1 |
|
为了节省将 numpy 数组复制到指定设备,然后又将结果存储到 numpy 数组中所浪费的时间,Numba 提供了一些 函数 来声明并将数组送到指定设备,如:numba.cuda.device_array,numba.cuda。 device_array_like,numba.cuda.to_device 等函数来节省不必要的复制到 cpu 的时间(除非必要)。
另一方面,设备函数 只能从设备内部(通过核函数或其他设备函数)调用。 比较好的一点是,您可以从 设备函数 中返
1 | from numba import cuda |
您还应该在这里查看 Numba 的 cuda 库支持的功能。
Numba 在其 cuda 库中也有自己的 原子操作,随机数生成器,共享内存实现(以加快数据的访问)等功能。
ctypes/cffi/cython 的互用性:
cffi– 在 nopython 模式下支持调用 CFFI 函数。ctypes– 在 nopython 模式下支持调用 ctypes 包装函数。- Cython 导出的函数是 可调用 的。
参考:
原始材料:
很有意义和价值的仓库,里面包含4 part,包括pytorch、Numba、Parallelization、Dask四种加速方式,这篇只是part 2
https://github.com/PuneetGrov3r/MediumPosts/tree/master/SpeedUpYourAlgorithms
博文:
英文:Speed Up your Algorithms Part 2— Numba
中文:用 Numba 加速 Python 代码,变得像 C++ 一样快
资料:
扩展阅读
- https://nbviewer.jupyter.org/github/ContinuumIO/gtc2017-numba/tree/master/
- https://devblogs.nvidia.com/seven-things-numba/
- https://devblogs.nvidia.com/numba-python-cuda-acceleration/
- https://jakevdp.github.io/blog/2015/02/24/optimizing-python-with-numpy-and-numba/
- https://www.youtube.com/watch?v=1AwG0T4gaO0