踏实学习,一步一步看懂
模型相关
首先需要了解基础的模型,在了解为什么Lattice+LSTM能够解决NER的问题
主要通过知乎一些blog和李宏毅老师的ML课程视频了解,尤其感谢李宏毅老师,其课程内容高效且有趣,PPT更是准备的十分用心,里面的示例图非常易懂!
RNN
模型特性
RNN(Recurrent Neural Network),顾名思义,是循环/递归神经网络,其与常规NN模型的差别在于,数据在模型中传递时,其得到的输出不仅仅由当前的输入决定,该数据之前的数据也会对其有影响,也就是不仅利用到当前数据的信息,也能够利用到与时序相关的前序输入的信息,这样能够解决什么问题呢?
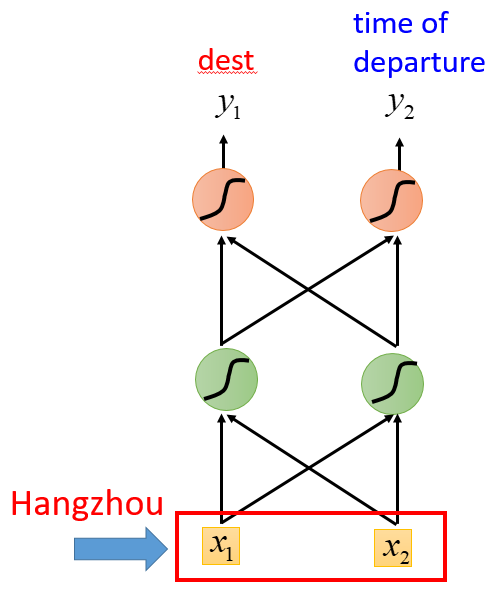
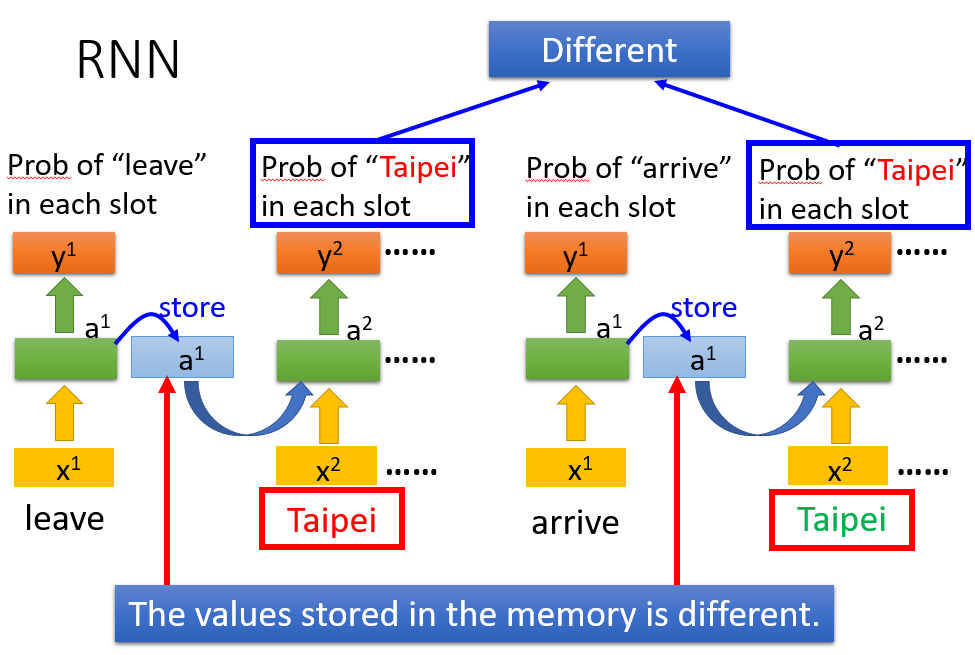
比如slot filling(语义槽填充)问题,同样的词语在不同语境下的含义是不同的,比如一个地点hangzhou,他的前面是 arrive 还是 leave 才决定了他是destination还是place of departure
所以RNN在需要利用时序信息、上下文信息的场景中十分适用,也就在NLP领域大放异彩
具体实现和原理
下方左图是传统的NN,右图则是RNN的基本示意图,即通过存储上一次输入的相关信息(专门存储的记忆,并非一定与输出相同),来一起决定此次输入的输出
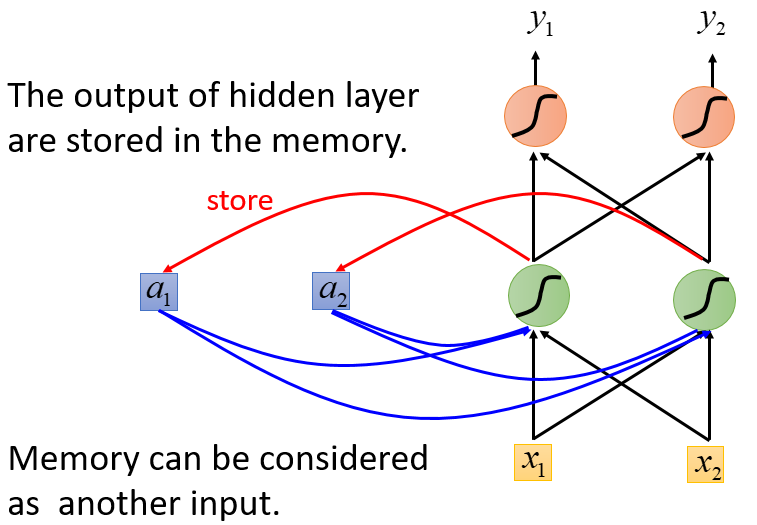
具体示例
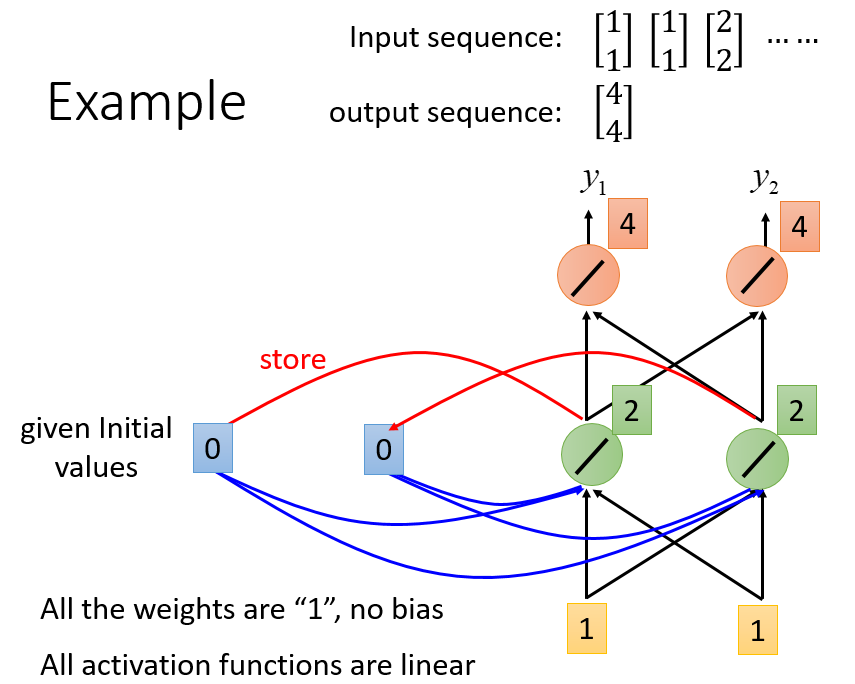
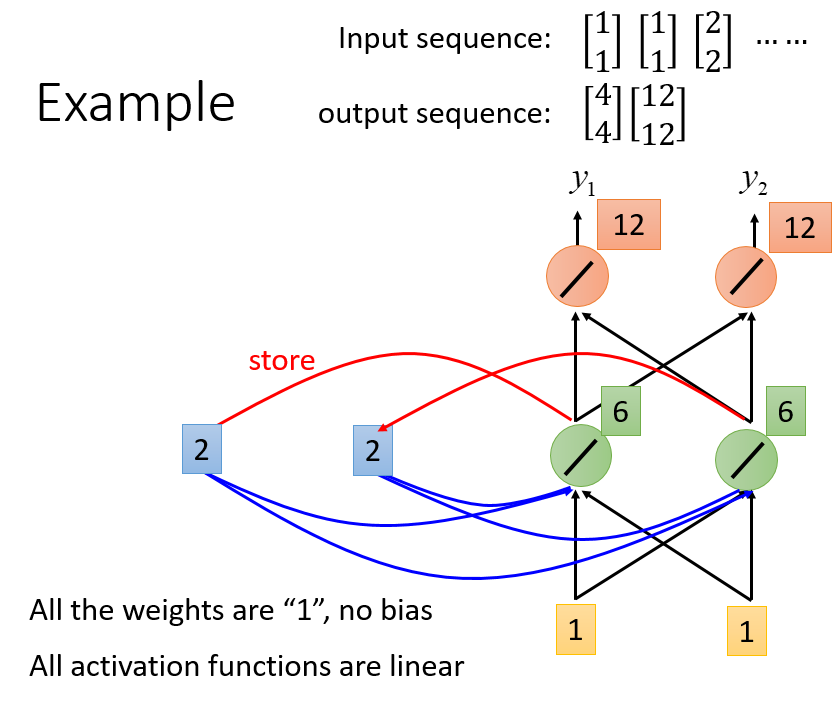
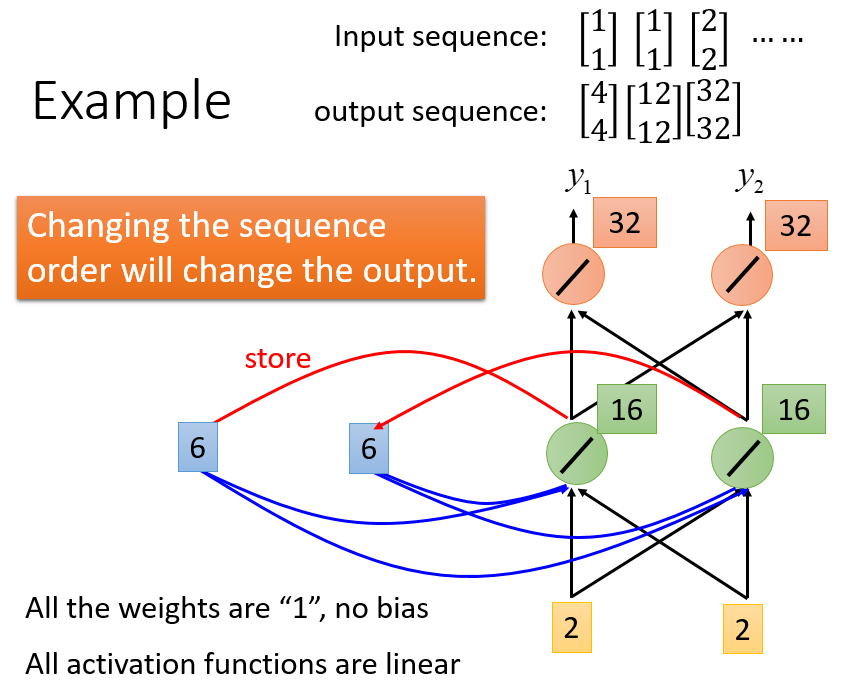
从而使得同一个词语的上文不同,其得到的结果也不同
改进形态
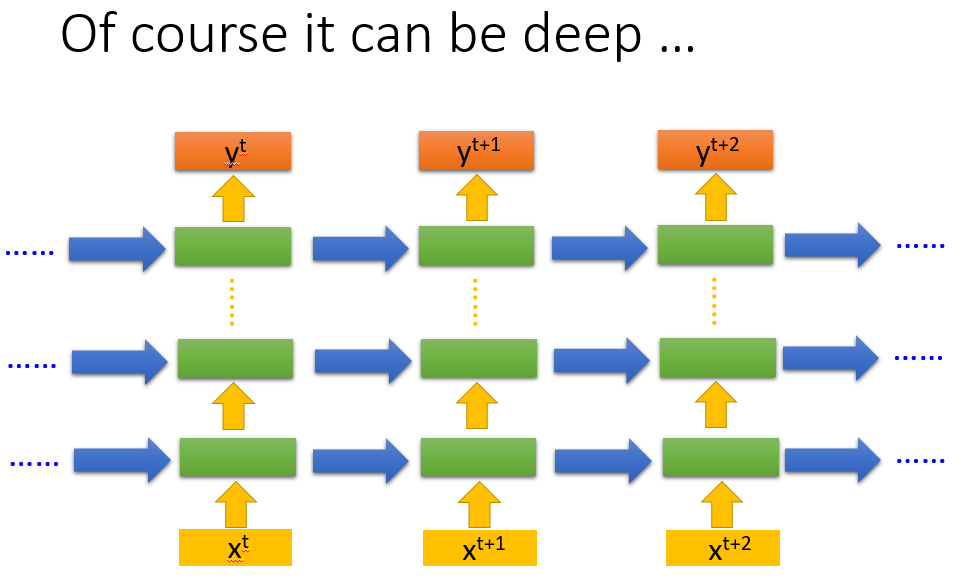
Deep RNN
多个Hidden layer,每个hidden layer都存下相应的memory用于后续数据的传递
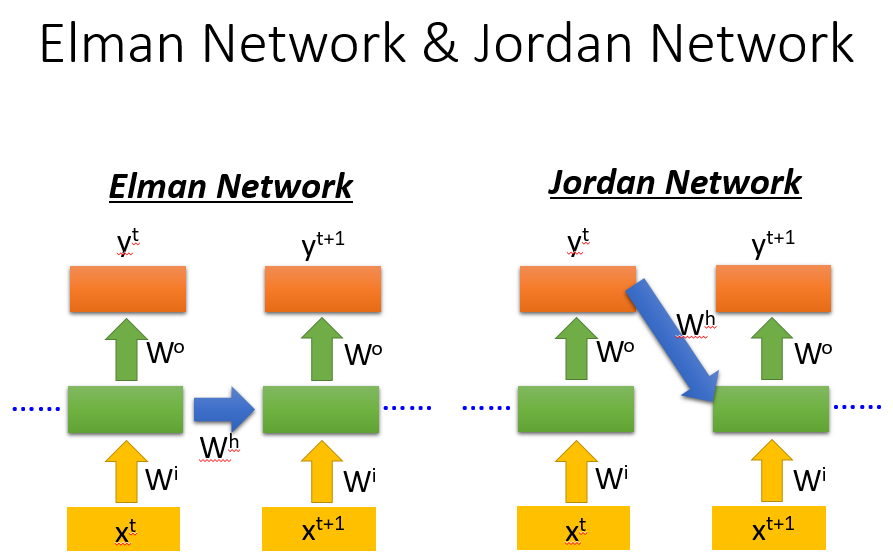
Elman Network & Jordan Network
Elman Network就是我们上述的基本模型,将hidden layer的数据进行传递,也存在Jordan Network是将上次数据的输出存下,JN可能会有更好的performance,因为hidden layer学习的feature可能不好解释和传递,因为不知道学到的是啥,但是JN学到的就是我们的target,便于理解
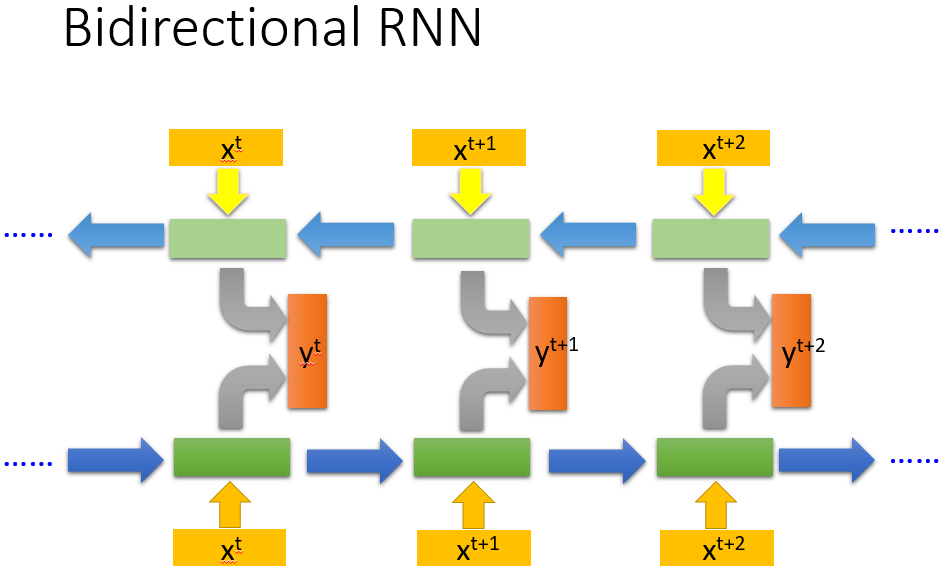
Bidirectional RNN
利用上、下文,将上文和下文得到的y,在进行组合学习
LSTM
模型特性
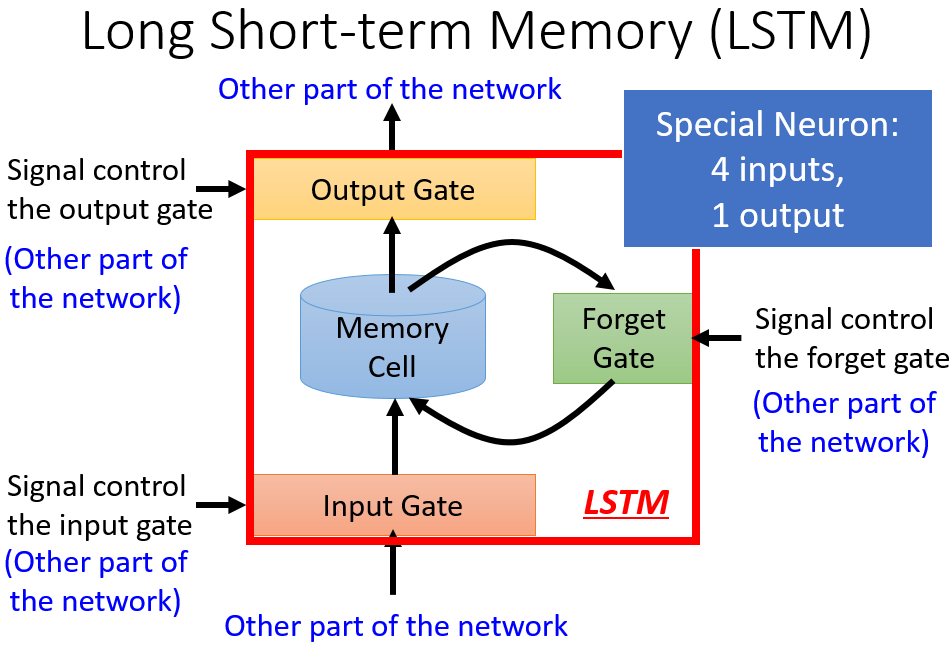
LSTM(Long short-term memory,LSTM)则是更特殊和robust的RNN,他不仅仅是利用到前序输入留下的memory,他同时还会有个多个门对整个过程进行处理,选择是否忘记memory、是否使用memory,所以他会将一个输入变成4个输入(x、input gate、forget gate、output gate),自己去学习如何使用memory
与RNN的结构差异
具体实现和原理
基本结构
模型传输过程
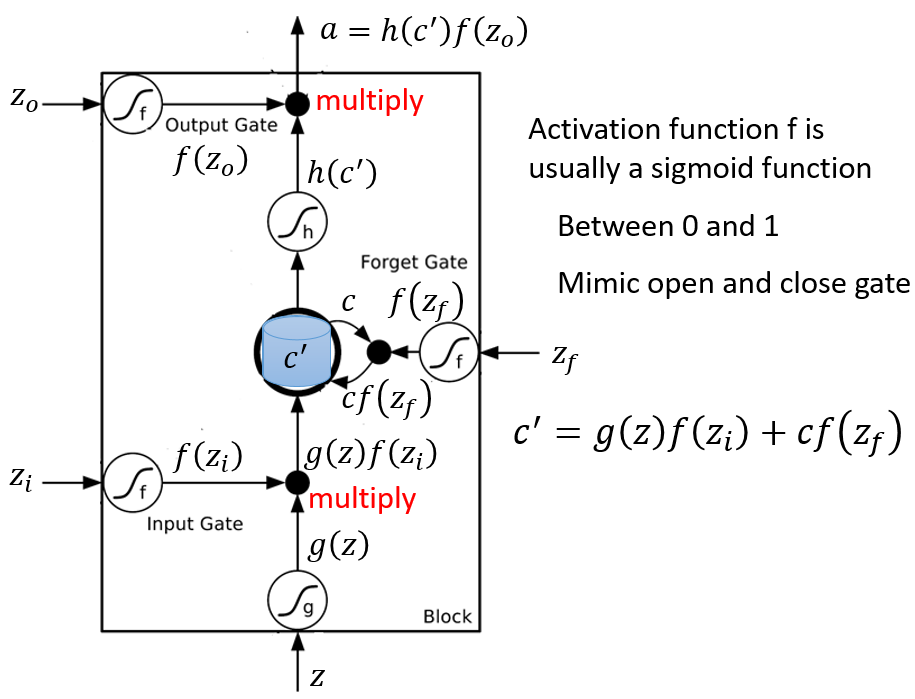
输入Z,然后先得到Z,Zi,Zo,Zf,总共4个输入,然后了解各个门的状态,然后输入Z经过g(Z)后与input gate的结果multiply,所以input gate决定是否这次要传入新的输入,然后C’就上一次存在memory的值,他乘上f(Zf),也就是forget gate决定是否要将存在memory里面的值忘掉,然后再加上前面input gate和输入multiply的结果,得到了接下来要存在memory里的C‘,最后是通过output gate进行最后的activate然后输出,所以output gate决定是否输出此次的结果
(与直觉和名字相反,forget gate打开的时候,代表C通过该门,也就是记住上一次的memory,关闭的时候,则忘记上一次的memory)
通常使用sigmoid函数,使其在0-1之间,0代表打开,1代表关上
传递过程的逻辑简化如下:
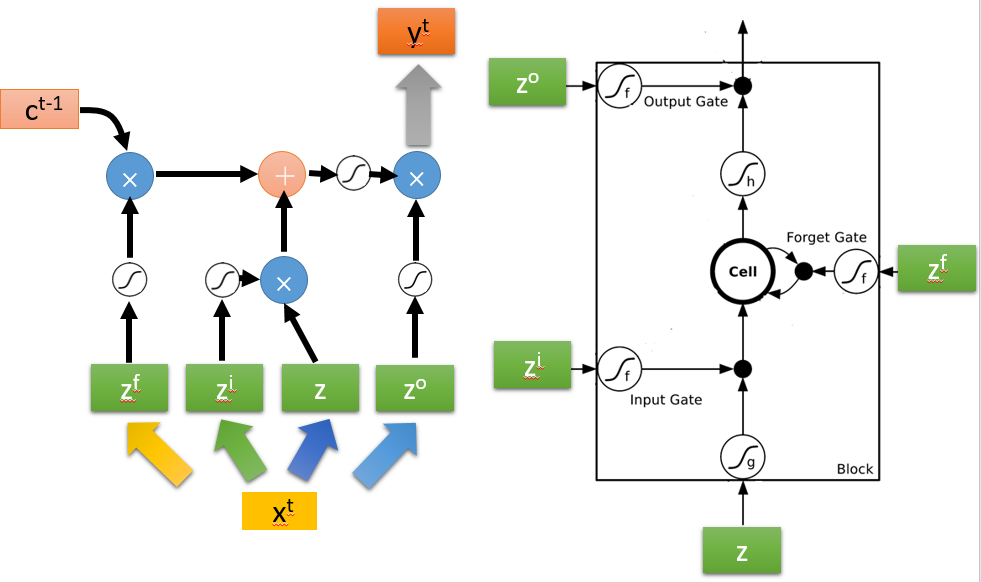
那么LSTM的传递过程则如下图
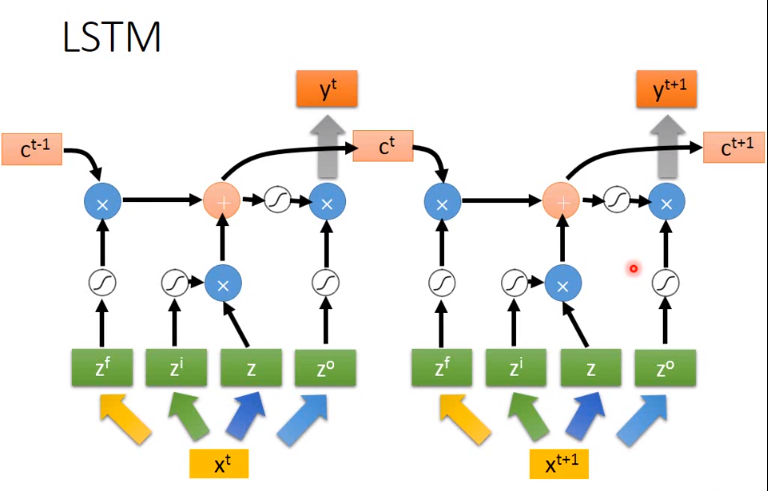
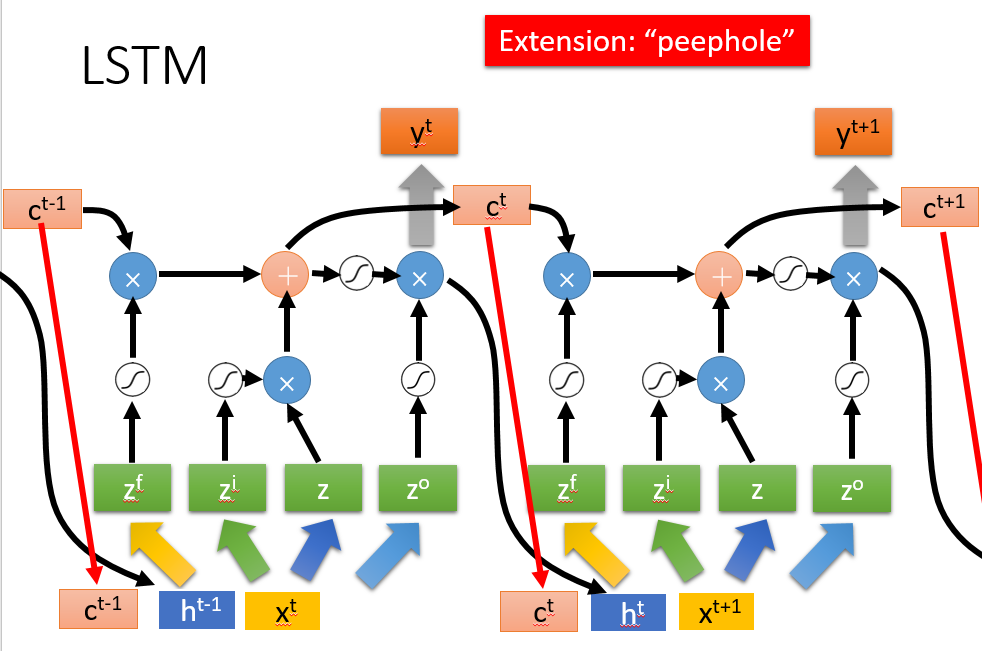
但是真正的LSTM会如下图,会将上一步的output gate之前的h也作为输入,还有peephole将memory的值作为了输入:
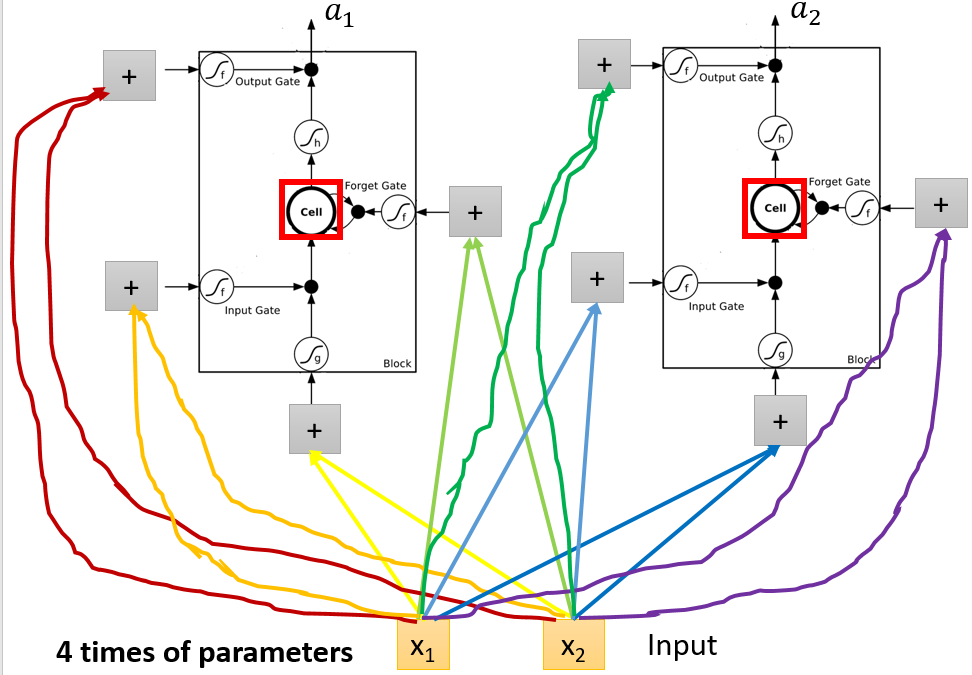
所以其实输入只有一个,但是要变成4个,所以会有四倍的参数,如:
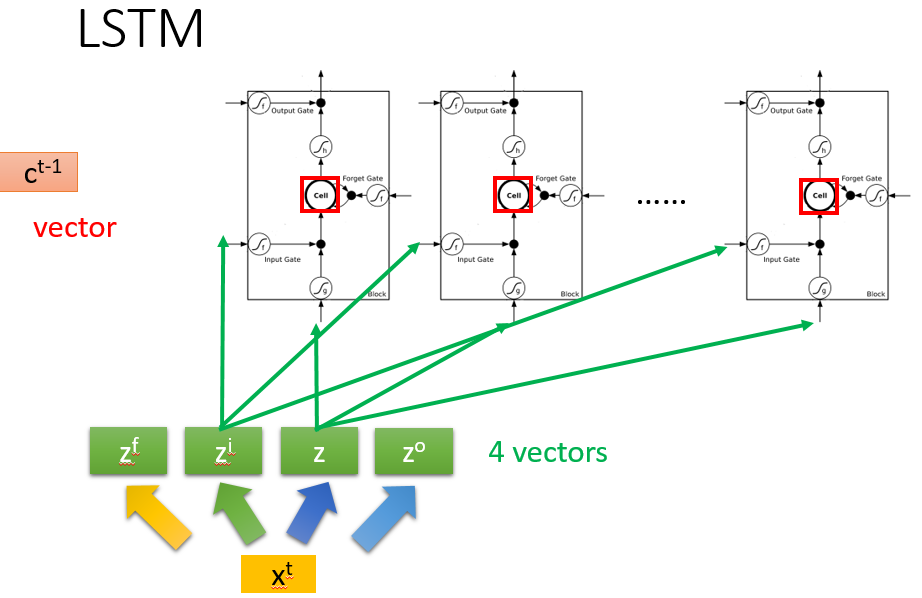
案例
图比较多,可以直接看李宏毅老师的PPT,一步步手推LSTM的样例,太强了!
总结
模型关系
LSTM是RNN的升级版,多了很多的gate对输入、memory、输出都进行了控制,从而能够记忆需要长时间记忆的、忘记不重要的信息,做到Long的short-term,所以现在各个框架里的RNN基础块就是LSTM,纯正的RNN一般叫simpleRNN,但是LSTM也存在问题,比如他的参数比较多,所以还要GRU作为改进的方式,少了1/3的参数
GRU输入输出的结构与普通的RNN相似,其中的内部思想与LSTM相似;与LSTM相比,GRU内部少了一个”门控“,参数比LSTM少,但是却也能够达到与LSTM相当的功能。考虑到硬件的计算能力和时间成本,因而很多时候我们也就会选择更加”实用“的GRU啦。
GRU可以一定程度上解决LSTM的overfitting,简单来说,GRU的思路就是“旧的不去,新的不来”,他会把input gate和forget gate联动,如果input打开,那么forget打开,忘掉原来的memory
具体可以参考:
人人都能看懂的LSTM - 陈诚的文章 - 知乎 https://zhuanlan.zhihu.com/p/32085405
人人都能看懂的GRU - 陈诚的文章 - 知乎 https://zhuanlan.zhihu.com/p/32481747
训练特点
问题
RNN也是通过BP进行训练,Backpropagation through time (BPTT),但是他会存在一个问题,就是梯度的变化很随机,可能是陡坡也可能是平原
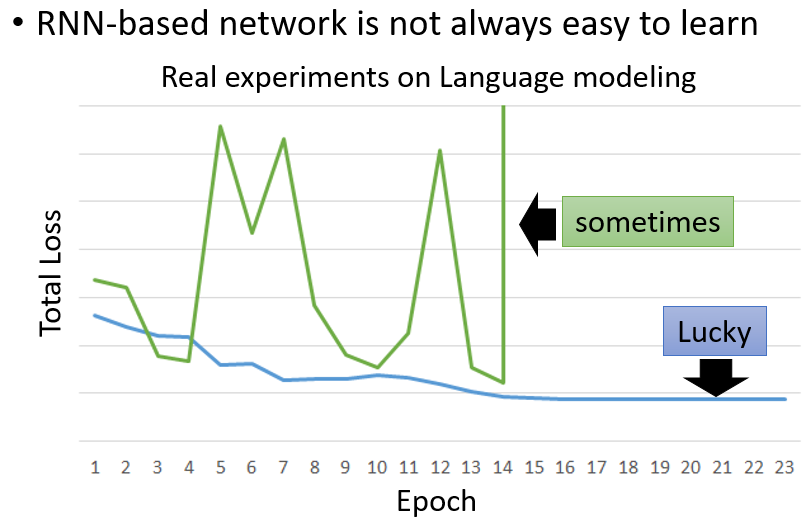
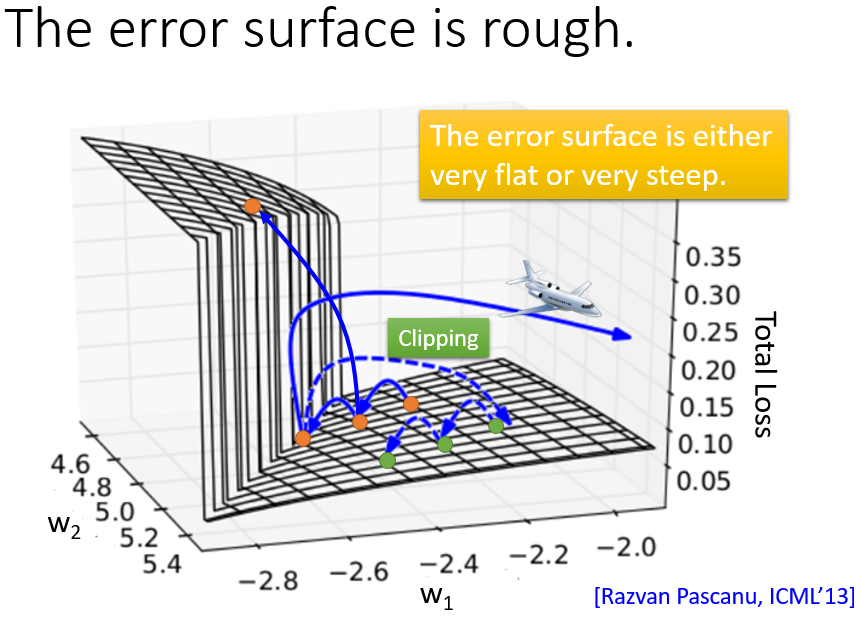
解决方案
梯度裁剪(clipping),当gradient大于某个threshold的时候,就截止,like gradient <= 15
为什么呢
为什么RNN很容易出现gradient vanish or gradient exploration,因为RNN此类模型中,会被前述的内容反复影响
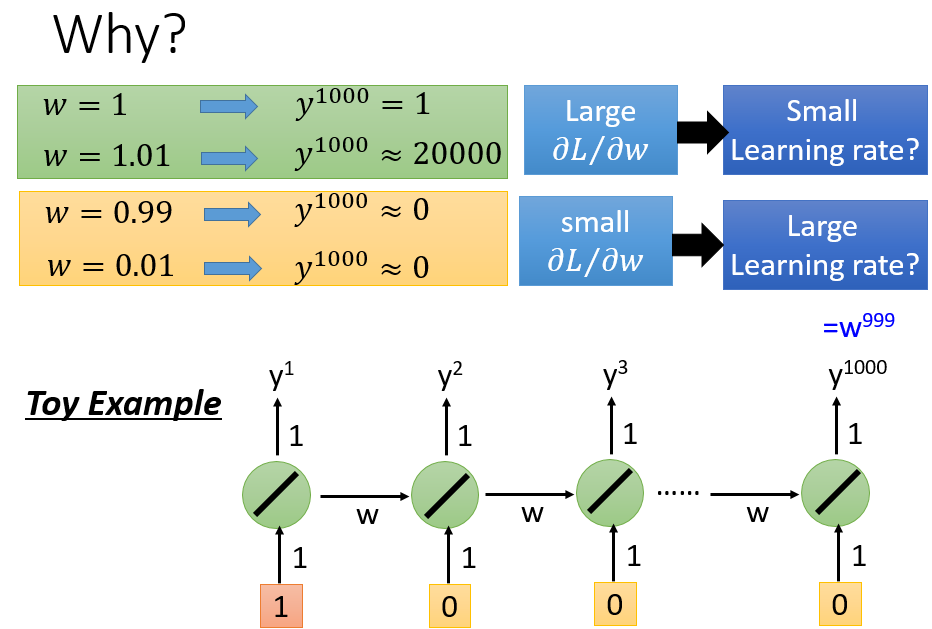
(一般RNN都用sigmoid,而非RELU)
但是LSTM不会有这个问题?LSTM可以handle前述RNN存在的gradient vanish问题,但是还可能会有较大的梯度,所以一般采取small learning rate
因为他的此次输入和memory之间是add,not multiply
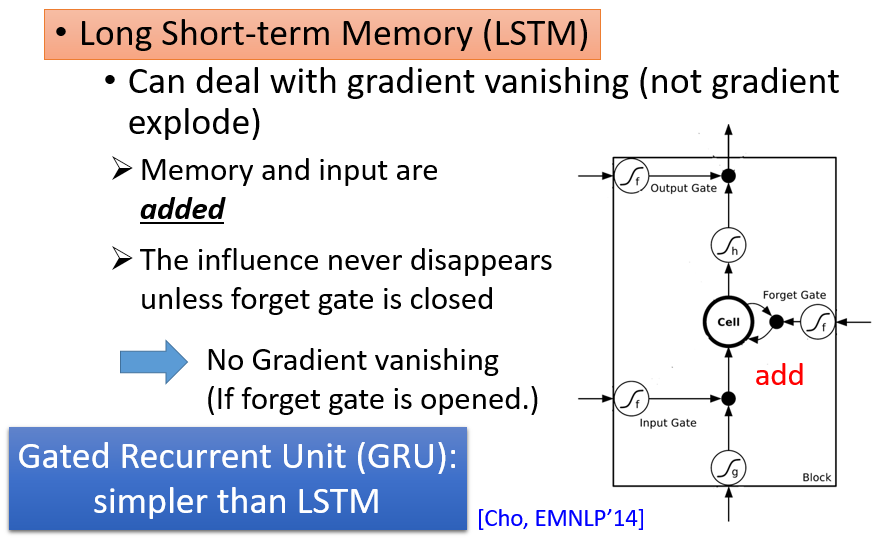
An idea from Hinton‘s paper: 用identit matrix+ReLU训练RNN可以超过LSTM
Deep VS Structured Leanring
Structured Leanring可以更加轻易地增加一下显性的规则或者约束,Deep可以有更灵活和更优的性能

结合二者
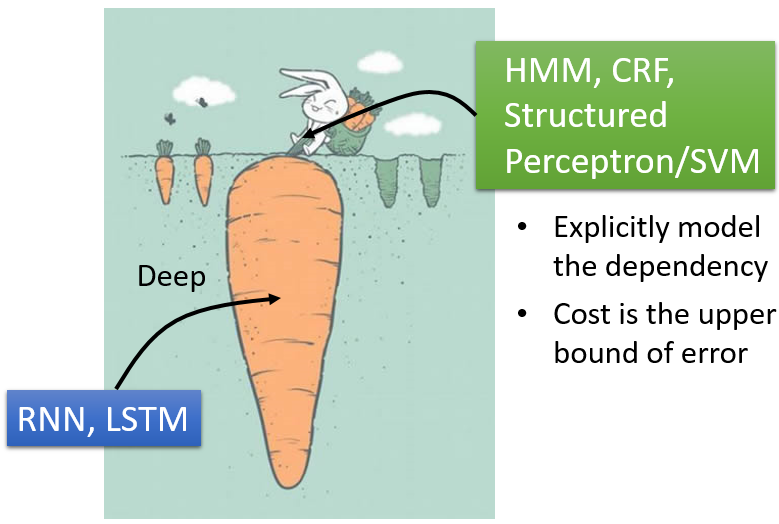
先通过LSTM等Deep model进行feature embedding,在通过structured learning进行学习
注意力机制/Attention/Transformer
推荐阅读:
深度学习中的注意力模型(2017版) - 张俊林的文章 - 知乎 https://zhuanlan.zhihu.com/p/37601161
一文看懂 Attention(本质原理+3大优点+5大类型) - 赵强的文章 - 知乎 https://zhuanlan.zhihu.com/p/91839581
详解Transformer (Attention Is All You Need) - 大师兄的文章 - 知乎 https://zhuanlan.zhihu.com/p/48508221
Attention机制详解(二)——Self-Attention与Transformer - 川陀学者的文章 - 知乎 https://zhuanlan.zhihu.com/p/47282410
从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 - 张俊林的文章 - 知乎 https://zhuanlan.zhihu.com/p/49271699
NER相关
NER问题
推荐阅读:
常用模型
Baseline:
NLP实战-中文命名实体识别 - MaggicQ的文章 - 知乎 https://zhuanlan.zhihu.com/p/61227299 :
通过pytorch作为主要工具实现不同的模型(包括HMM,CRF,Bi-LSTM,Bi-LSTM+CRF)来解决中文命名实体识别问题,文章不会涉及过多的数学推导,但会从直观上简单解释模型的原理
对应的代码库:https://github.com/luopeixiang/named_entity_recognition 上面的介绍只是部分,更全的代码和完整的工程(包括数据集的导入、处理到最后的评测)在github的仓库上
HMM解码所用的viterbi:
如何简单地理解维特比算法(viterbi算法)? - 石溪的回答 - 知乎 https://www.zhihu.com/question/294202922/answer/1631974168
CRF:
如何轻松愉快地理解条件随机场(CRF)? - 忆臻的文章 - 知乎 https://zhuanlan.zhihu.com/p/104562658
通俗易懂!BiLSTM上的CRF,用命名实体识别任务来解释CRF(一) - 忆臻的文章 - 知乎 https://zhuanlan.zhihu.com/p/119254570
BiLSTM+CRF
模型相关资料
基本模型:HMM CRF BiLSTM BiLSTM+CRF NLP实战-中文命名实体识别 - MaggicQ的文章 - 知乎 https://zhuanlan.zhihu.com/p/61227299
维特比算法:如何简单地理解维特比算法(viterbi算法)? - 石溪的回答 - 知乎 https://www.zhihu.com/question/294202922/answer/1631974168
损失函数:通俗易懂!BiLSTM上的CRF,用命名实体识别任务来解释CRF(一) - 忆臻的文章 - 知乎 https://zhuanlan.zhihu.com/p/119254570
LSTM+CRF 解析(原理篇) - visionshao的文章 - 知乎 https://zhuanlan.zhihu.com/p/97829287
代码相关资料
pytorch tutorial https://pytorch.org/tutorials/beginner/nlp/advanced_tutorial.html#bi-lstm-conditional-random-field-discussion
pytorch中LSTM的输入输出格式 https://www.cnblogs.com/picassooo/p/13470992.html
pack_padded_sequence 和 pad_packed_sequence https://zhuanlan.zhihu.com/p/342685890
LSTM为什么需要后接CRF呢?
因为LSTM只能学到输入数据(特征)的上下文关系,但是并没有利用到label的上下关系
(如何理解LSTM后接CRF? - RandomWalk的回答 - 知乎 https://www.zhihu.com/question/62399257/answer/325334144)
具体来说
首先我们要知道为什么使用LSTM+CRF,序列标注问题本质上是分类问题,因为其具有序列特征,所以LSTM就很合适进行序列标注,确实,我们可以直接利用LSTM进行序列标注。但是这样的做法有一个问题:每个时刻的输出没有考虑上一时刻的输出。我们在利用LSTM进行序列建模的时候只考虑了输入序列的信息,即单词信息,但是没有考虑标签信息,即输出标签信息。这样会导致一个问题,以“我 喜欢 跑步”为例,LSTM输出“喜欢”的标签是“动词”,而“跑步”的标签可能也是“动词”。但是实际上,“名词”标签更为合适,因为“跑步”这里是一项运动。也就是“动词”+“名词”这个规则并没有被LSTM模型捕捉到。也就是说这样使用LSTM无法对标签转移关系进行建模。而标签转移关系对序列标注任务来说是很重要的,所以就在LSTM的基础上引入一个标签转移矩阵对标签转移关系进行建模。这就和CRF很像了。我们知道,CRF有两类特征函数,一类是针对观测序列与状态的对应关系(如“我”一般是“名词”),一类是针对状态间关系(如“动词”后一般跟“名词”)。在LSTM+CRF模型中,前一类特征函数的输出由LSTM的输出替代,后一类特征函数就变成了标签转移矩阵。
(LSTM+CRF 解析(原理篇) - visionshao的文章 - 知乎 https://zhuanlan.zhihu.com/p/97829287)
中文NER
推荐阅读:
中文NER的正确打开方式: 词汇增强方法总结 (从Lattice LSTM到FLAT)
NER中的词汇增强方法(LatticeLSTM、CGN、FLAT、Simple-Lexicon)
为什么中文的NER要单独拿出来说呢?因为与英文中单词是固定的,而我们中文的实体词汇是通过“字”组成的,那么在处理时,英文只需要直接根据单词进行处理,而中文如果仅通过字符进行处理,基于字符的NER没有利用词汇信息,而词汇边界对于实体边界通常起着至关重要的作用
但是如果先通过分词再进行NER,那么后续的NER就很依赖前面分词的结果,而往往中文句子的分词很难,比如“南京市长江大桥”、“小龙女说我也想过过过儿过过的生活”、“一把把把把住了*
所以要想通过词汇增强的方式增强中文NER问题,需要下一些功夫,也就引出了本文的重点Lattice-LSTM
Lattice-LSTM
本文是基于词汇增强方法的中文NER的开篇之作,提出了一种Lattice LSTM以融合词汇信息。
具体地,当我们通过词汇信息(词典)匹配一个句子时,可以获得一个类似Lattice的结构。
Lattice是一个有向无环图,词汇的开始和结束字符决定了其位置。Lattice LSTM结构则融合了词汇信息到原生的LSTM中:
如上图所示,Lattice LSTM引入了一个word cell结构,对于当前的字符,融合以该字符结束的所有word信息,如对于「店」融合了「人和药店」和「药店」的信息。对于每一个字符,Lattice LSTM采取注意力机制去融合个数可变的word cell单元,其主要的数学形式化表达为:
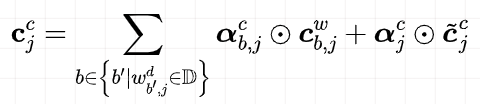
本文不再堆砌繁杂的数学公式,具体看参考原论文。需要指出的是,当前字符有词汇融入时,则采取上述公式进行计算;如当前字符没有词汇时,则采取原生的LSTM进行计算。当有词汇信息时,Lattice LSTM并没有利用前一时刻的记忆向量 ,即不保留对词汇信息的持续记忆。
Lattice LSTM 的提出,将词汇信息引入,有效提升了NER性能;但其也存在一些缺点:
- 「计算性能低下,不能batch并行化」。究其原因主要是每个字符之间的增加word cell(看作节点)数目不一致;
- 「信息损失」:1)每个字符只能获取以它为结尾的词汇信息,对于其之前的词汇信息也没有持续记忆。如对于「药」,并无法获得‘inside’的「人和药店」信息。2)由于RNN特性,采取BiLSTM时其前向和后向的词汇信息不能共享。
- 「可迁移性差」:只适配于LSTM,不具备向其他网络迁移的特性。